1. Convolution Neuarl Network
CNN은 feature extraction을 위한 convolution 부분과 fully connected된 layer 층으로 구성되있다.
featuer extraction은 이미지 데이터의 localized 특성을 파악하기 위한 부분이다.
feature 별 filter와 이미지 map을 convolution 연산하여 새로운 map을 생성하며 이는 feature와 유사할수록 큰 값을 갖는다.
2. 합성곱 GAN 실습
0. 라이브러리
import torch
import torch.nn as nn
from torch.utils.data import Dataset
import cv2 as cv
import os
import numpy as np
import pandas, random
import matplotlib.pyplot as plt1. 학습 데이터 세팅
! mkdir dataset_3000.zip # 마운트에 폴더 생성
! unzip dataset_3000.zip -d ./dataset_3000 # unzip데이터 배열 저장 및 augmentation
src = '/content/dataset_3000/'
# 이미지 읽기
def img_read(src,file):
img = cv.imread(src+file)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
img=img.reshape(28,48,3,1)
img=np.transpose(img)
return img
# 좌우반전 읽기
def img_leftright(src,file):
origin = cv.imread(src+file)
origin = cv.cvtColor(origin, cv.COLOR_BGR2RGB)
img = cv.flip(origin,1)
img=img.reshape(28,48,3,1)
img=np.transpose(img)
return img
# 블러 읽기
def img_blur(src,file):
origin = cv.imread(src+file)
origin = cv.cvtColor(origin, cv.COLOR_BGR2RGB)
img = cv.medianBlur(origin,3)
img=img.reshape(28,48,3,1)
img=np.transpose(img)
return img
#밝기 읽기
def img_bright(src,file):
origin = cv.imread(src+file)
origin = cv.cvtColor(origin, cv.COLOR_BGR2RGB)
img = cv.add(origin,50)
img=img.reshape(28,48,3,1)
# img=np.transpose(img)
return img
# src 경로에 있는 파일 명을 저장
files = os.listdir(src)
data_set = []
# 경로와 파일명을 입력으로 넣어 확인
# 데이터를 255로 나눠서 0~1사이로 정규화
for file in files:
data_set.append(img_leftright(src,file)/255.)
for file in files:
data_set.append(img_read(src,file)/255.)
for file in files:
data_set.append(img_blur(src,file)/255.)
for file in files:
data_set.append(img_bright(src,file)/255.)
# array로 데이터 변환
data_set = np.array(data_set)
print('shape:',np.shape(data_set[0]))
print('list shape:',np.shape(data_set))#실행 결과
shape: (1, 3, 48, 28)
list shape: (11484, 1, 3, 48, 28)plt.imshow(np.transpose(data_set[500][0]))
데이터 출처 : https://www.kaggle.com/mahmoudima/mma-facial-expression
MMA FACIAL EXPRESSION
Facial expression images
www.kaggle.com
학습 데이터 : 얼굴 데이터의 눈 부분 추출
2. 분류기 생성 및 테스트
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,256,kernel_size=3,stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256,256,kernel_size=3,stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256,3,kernel_size=3,stride=2),
nn.LeakyReLU(0.2),
View(3*10),
nn.Linear(3*10,1),
nn.Sigmoid()
)
self.loss_function = nn.BCELoss()
self.optimiser = torch.optim.Adam(self.parameters(),lr=0.0001)
self.counter = 0;
self.progress = []
pass
def forward(self,inputs):
return self.model(inputs)
def train(self,inputs,targets):
outputs = self.forward(inputs)
loss = self.loss_function(outputs,targets)
self.counter +=1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 1000 == 0):
print("counter = ", self.counter)
pass
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5, 1.0, 5.0))
pass
passD = Discriminator()
for image_data in data_set:
D.train(torch.Tensor(image_data), torch.FloatTensor([1.0]))
D.train(generate_random_image((1,3,48,28)),torch.FloatTensor([0.0]))
pass
D.plot_progress()3. 생성기 생성 및 테스트
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(54,3*13*23),
nn.LeakyReLU(0.2),
View((1,3,13,23)),
nn.ConvTranspose2d(3,256,kernel_size=3,stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256,256,kernel_size=3,stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256,3,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(3),
nn.Sigmoid()
)
self.optimiser = torch.optim.Adam(self.parameters(),lr=0.0001)
self.counter = 0;
self.progress = []
pass
def forward(self,inputs):
return self.model(inputs)
def train(self,D,inputs,targets):
g_output = self.forward(inputs)
d_output = D.forward(g_output)
loss = D.loss_function(d_output,targets)
self.counter +=1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 1000 == 0):
print("counter = ", self.counter)
pass
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5, 1.0, 5.0))
pass
passG = Generator()
output = G.forward(generate_random_seed(54))
img = output.detach().permute(0,2,3,1).reshape(3,48,28)
plt.imshow(np.transpose(img), interpolation='none', cmap='Blues')
4. GAN 학습 및 결과
D = Discriminator()
G = Generator()
epochs = 1
for epoch in range(epochs):
print ("epoch = ", epoch + 1)
for image_data in data_set:
D.train(torch.Tensor(image_data),torch.FloatTensor([1.0]))
D.train(G.forward(generate_random_seed(54)).detach(),torch.FloatTensor([0.0]))
G.train(D,generate_random_seed(54),torch.FloatTensor([1.0]))
pass
passD.plot_progress()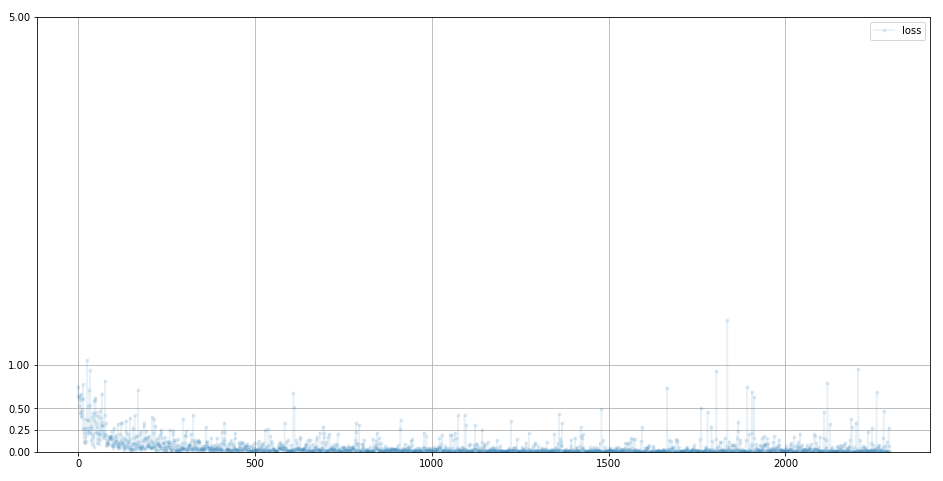
G.plot_progress()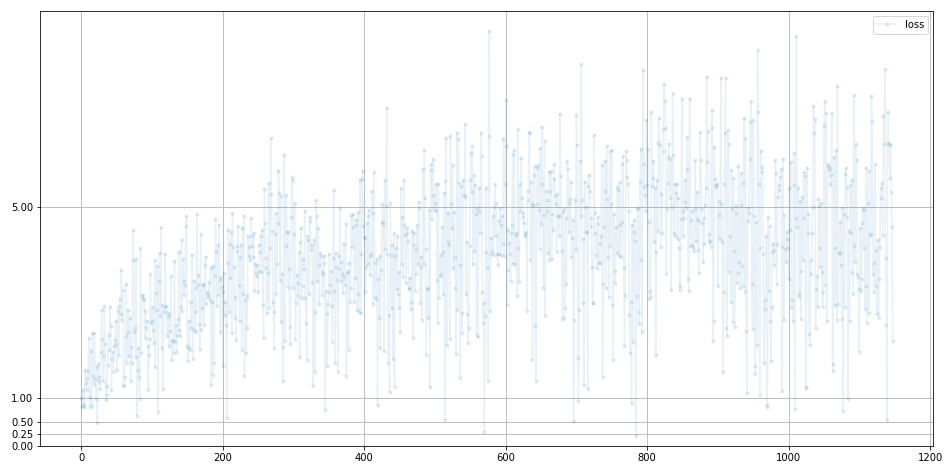
f, axarr = plt.subplots(2,3, figsize=(16,8))
for i in range(2):
for j in range(3):
output = G.forward(generate_random_seed(54))
img = output.detach().permute(0,2,3,1).reshape(3,48,28)
axarr[i,j].imshow(np.transpose(img), interpolation='none',cmap='Blues')
pass
pass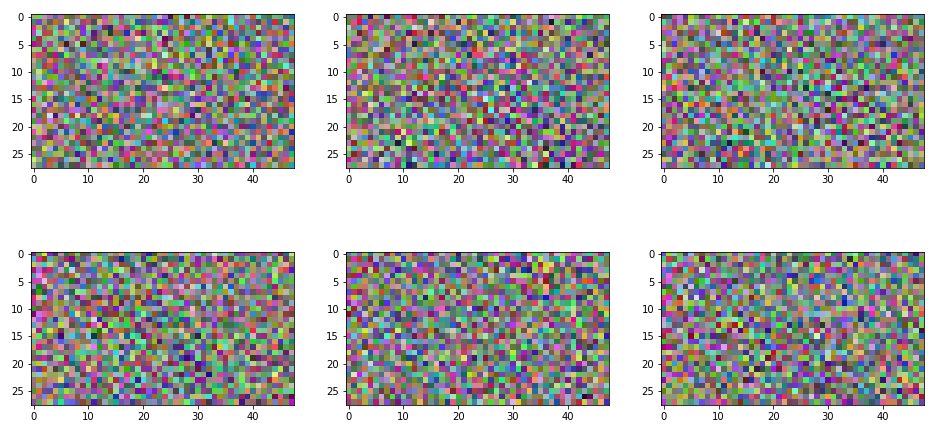
3. 고찰 및 분석
분류기의 loss 값은 0에 수렴하는 것으로 보아 분류 성능이 좋은 것을 알 수 있다.
반면 생성기의 loss 값이 커지는 경향으로 보아 학습이 제대로 이루어 지지 않은 것을 알 수 있다.
학습에 이용한 데이터가 대략 10000개로 충분하지 않은 것이 생성기의 큰 loss 값 발생 원인 중 하나로 생각 된다.
'Group Study (2021-2022) > Machine Learning (GAN)' 카테고리의 다른 글
| [Machine Learning] 7주차 스터디-CycleGAN (0) | 2021.11.28 |
|---|---|
| [Machine Learning] 6주차 스터디-조건부 GAN (0) | 2021.11.22 |
| [Machine Learning] 3주차 스터디 - 파이토치와 신경망 기초 (0) | 2021.11.08 |
| [Machine Learning] 4주차 스터디-튼튼한 GAN 만들기 (0) | 2021.10.31 |
| [Machine Learning] 2주차 스터디 - 심층 신경망 성능 향상 시키기, 합성곱 신경망 네트워크(CNN) (0) | 2021.10.12 |