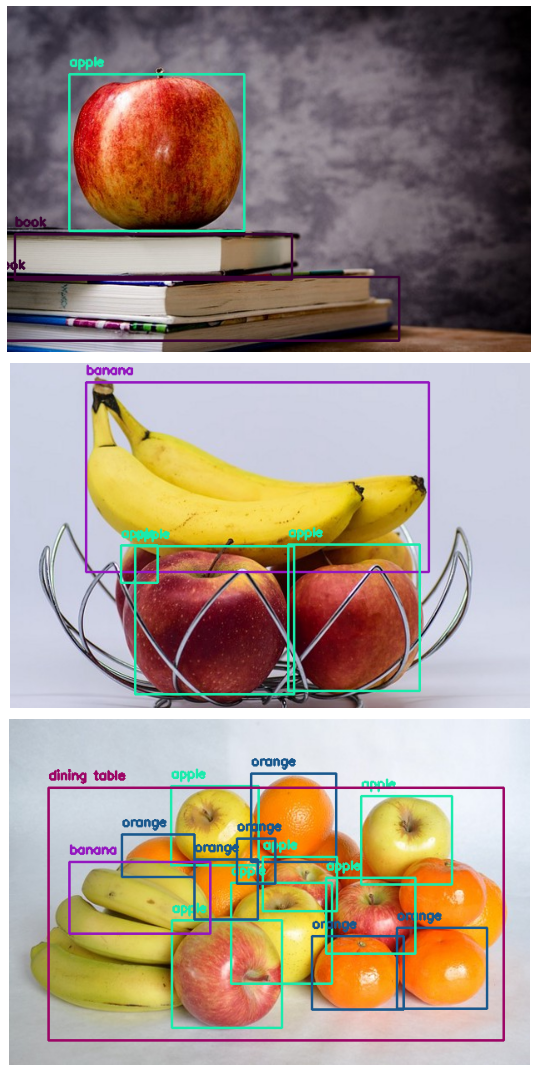
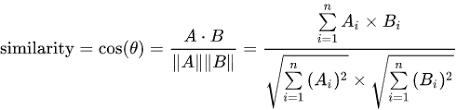
1. 이미지 내 문자 인식(OCR) 맛보기 1) tesserocr 라이브러리 설치 Anaconda 터미널에서 가상환경(ex. MLStudy)을 activate 하고 tesserocr를 설치합니다. (base) >conda activate MLStudy (MLStudy) >conda install -c conda-forge tesserocr tesserocr 라이브러리 관련 추가 설명이나 다른 설치 방법은 링크를 참고하세요 : tesserocr · PyPI 가상환경에서 Jupyter Notebook를 실행해 tessorocr의 버전과 언어를 확인합니다. import tesserocr from PIL import Image print(tesserocr.tesseract_version()) # print te..