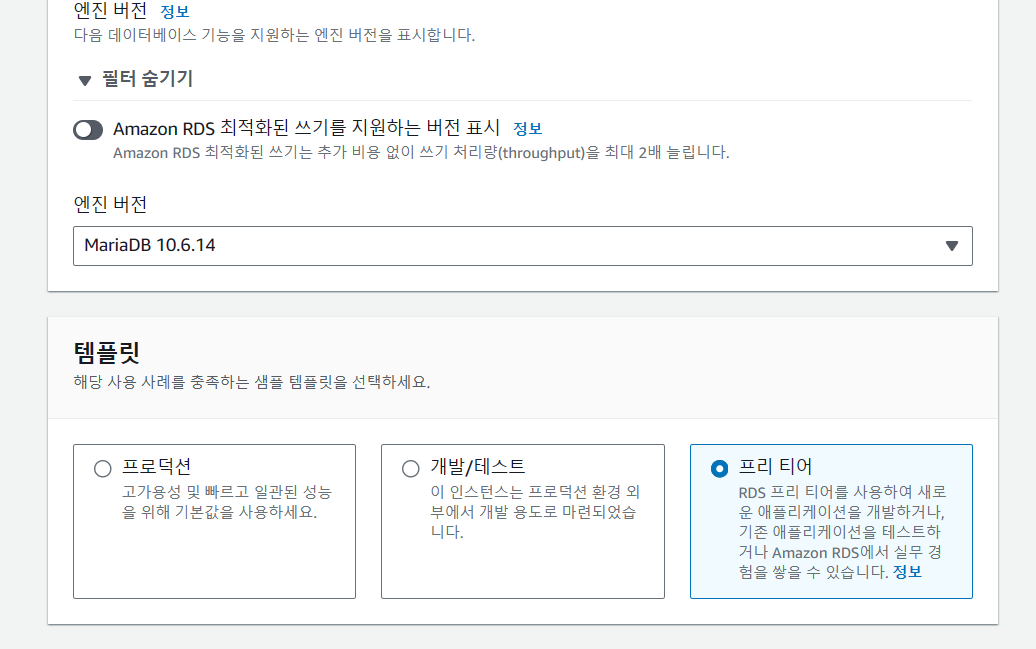
Chap 07_AWS에 데이터 베이스 환경을 만들어보자(AWS RDS) 웹 서비스의 백엔드를 다룬다고 했을 때 애플리케이션 코드를 작성하는 것 만큼 중요한 것이 데이터베이스를 다루는 것이다. 규모가 있는 회사의 경우 데이터베이스를 전문적으로 처리하는 직군 담당자들이 존재하지만 스타트업이나 개발 인원수가 적은 서비스에서는 개발자가 데이터베이스를 다뤄야만 하므로 백엔드 개발자는 데이터베이스를 다룰 줄 알야야 한다. AWS에서 제공하는 관리형 서비스인 RDS를 이용하여 데이터베이스를 구축하고 앞 장에서 만든 EC2 서버와 연동해볼 수 있다. RDS란? AWS에서 지원하는 클라우드 기반 관계형 데이터베이스 하드웨어 프로비저닝, 데이터베이스 설정, 패치 및 백업과 같이 잦은 운영 작업을 자동화하여 개발자가 개발에..