6-1 인공 신경망
케라스로 MNIST 패션 데이터를 받아와 이를 분류하는 작업을 한다.
train set이 매우 많아 SGD를 사용한다.
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter=5, random_state=42) # max_iter: 반복횟수
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))SGDClassifier와 cross_validate 함수를 사용하여 교차검증으로 성능을 확인해본다. max_iter를 5에서 20으로 늘려 반복횟수를 증가해도 성능이 많이 오르지 않음을 확인함.
cf. SGD Classifier 모델은 패션 MNIST 데이터의 클래스를 가능한 잘 구분할 수 있도록 10개의 방정식에 대한 모델 파라미터(가중치와 절편)를 찾는다.
각 클래스에 대한 선형방정식을 모두 계산한 다음 소프트맥스 함수를 통과하여 각 클래스에 대한 확률을 얻을 수 있다.
- 텐서플로 : 구글이 공개한 딥러닝 라이브러리
- 케라스 : 텐서플로의 고수준 API
인공신경망으로 모델 만들기
확률적 경사하강법을 사용한 로지스틱 회귀 모델이 가장 간단한 인공신경망이다.
신경망의 구성
Input Layer (입력층) - 입력 뉴런들로 구성된 층
Output Layer (출력층) - 결과물을 생성하는 출력 뉴런
Hidden Layer (은닉층) - 입력층과 출력층 사이에 있는 layer.
신경망 학습의 순서
1. 데이터 입력받음
2. layer에 도달할 때마다 해당 층의 가중치를 사용하여 출력 값을 계산
3. 모든 layer에서 반복.
4. 예측 값은 실제값과 비교하는 손실함수를 통해서 점수를 계산함
5. 해당 점수를 피드백으로 삼아서 loss 가 감소되는 방향으로 weight 가중치 수정
6. loop
7. loss function을 통해 loss를 최소화시키는 weight를 찾음
용어정리
weight : 뉴런 사이의 연결 강도
bias : 뉴런의 가중치
acvitation function 활성함수 : 주어진 입력값들을 받은 뉴런의 출력값들을 돌려주는 함수
인공신경망을 학습시키기 위해 데이터셋을 나눈다.
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)로지스틱 회귀에서는 교차 검증을 사용해 모델을 평가했지만, 인공신경망에서는 교차검증을 잘 사용하지 않고 검증 세트를 별도로 덜어내어 사용한다 (validation dataset.)
이유1: 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증검수가 안정적이다.
이유2: 교차검증을 수행하기에는 train시간이 너무 오래 걸리기 때문이다.
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))dense layer를 만들었다. 괄호 안의 내용을 순서대로 알아보자.

10 : 뉴런 개수
-> 10개의 패션 아이템이므로
activation='softmax" : 뉴런의 출력에 적용할 함수, 활성화 함수.
-> 10개의 뉴런에서 출력되는 값을 확률로 바꾸기 위해서는 소프트맥스 함수를 사용함.
input_shape=(784,) : 입력의 크기
-> 10개의 뉴런이 각각 몇 개의 입력을 받는지 튜를로 지정함.
model = keras.Sequential(dense) # dense 층을 가진 신경망 모델을 생성함.model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')compile을 통해 케라스 모델 훈련 전 설정을 한다.
loss='sparse_categorical_crossentropy' : 손실함수의 종류를 지정함
metrics='accuracy' : 훈련 과정에서 계산하고 싶은 측정값을 지정함
- Sparse Categorical Crossentropy : 정수로 된 타깃값을 사용해 크로스엔트로피 손실을 계산한다.
- Categorical Crossentropy : 타깃값을 원-핫 인코딩으로 준비했을 때.
model.fit(train_scaled, train_target, epochs=5) # 모델 훈련
model.evaluate(val_scaled, val_target) # 모델 성능 평가.이전에 훈련했던 것보다 신경망을 사용했을 때 성능이 올라간 것을 확인함.
6-2 심층 신경망

dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')인공신경망 모델에 dense1, 2로 층을 2개 출력해본다. 입력층과 출력층 사이에 밀집층이 추가된 것.
은닉층 : 이렇게 입력층과 출력층 사이에 있는 모든 층을 은닉층이라고 부른다.

활성화 함수 : 신경망 층의 선형방정식의 계산 값에 적용하는 함수
출력층의 활성화 함수 : 이진 분류일 경우 - 시그모이드 함수 사용, 다중분류일 경우 - 소프트맥스 함수
은닉층의 활성화 함수 : 비교적 자유롭다. 시그모이드, 렐루 등을 사용.
cf. 회귀를 위한 신경망의 출력층에는 activation 매개변수에 아무런 값을 지정하지 않는다.
심층 신경망 만들기
# dense1 객체와 dense2 객체를 Sequential 클래스에 추가하여 심층 신경망 DNN을 만든다.
model = keras.Sequential([dense1, dense2])
# 여러 개의 층을 추가하려먼 리스트로 만들어 전달해야 한다. 주의할 것은 출력층을 가장 마지막에 두어야 한다는 것.model.summary()summary 메서드로 층에 대한 유용한 정보를 얻을 수 있다.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 100) 78500
dense_2 (Dense) (None, 10) 1010
=================================================================
Total params: 79510 (310.59 KB)
Trainable params: 79510 (310.59 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________출력 크기 (None, 100) : 샘플의 개수, 은닉층의 뉴런 개수
샘플 개수가 None인 이유 : 배치 차원, 미니배치 경사하강법을 사용하여 샘플 개수를 고정하지 않고 미니배치 매개변수로 바꿀 수 있도록 유연하게 대응하기 위함
100 : 은닉층의 뉴런 개수, 즉 샘플마다 784의 픽셀값이 은닉층을 통과하면서 100개의 특성으로 압축된다.
784 * 100 + 100 = 78500개의 파라미터
100*10 + 10 = 1010개의 파라미터
78500 + 1010 = 79510개의 총 모델 파라미터 개수
그 아래 경사하강법으로 훈련되지 않는 파라미터의 개수를 의미하며, 0으로 나온다.
층을 추가하는 다른 방법
1. 따로 dense에 저장하지 않고 Sequential 클래스의 생상자 안에서 바로 Dense 클래스의 객체를 만드는 방법
-> 추가되는 층을 한 눈에 쉽게 알아보는 장점이 있다.
-> name 매개변수를 이용하여 층 구분이 쉽다
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')2. add로 바로 동적으로 층을 전달할 수 있다.
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))
활성화 함수
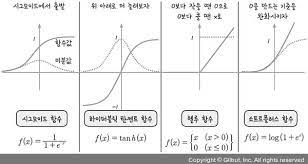
렐루 함수
시그모이드 함수의 경우 오른쪽과 왼쪽 끝으로 갈수록 그래프가 누워있기 때문에 올바른 출력을 만드는 데 신속하게 대응하지 못한다. 따라서 다른 종류의 활성화 함수인 렐루가 제안됨.
입력이 양수일 경우 마치 활성화 함수가 없는 거서럼 그냥 입력을 통과시키고 음수일 경우에는 0으로 만든다.
- max(0, z)와 같이 쓸 수 있다.
- z가 0보다 크면 z를 출력하고 z가 0보다 작으면 0을 출력함.
- 이미지 처리에서 뛰어나다.
tanh 함수
실수 값을 (-1, 1) 범위로 압축하는 활성화 함수이다. 원점을 중심으로 하여 값이 양의 무한대로 갈수록 1에 수렴하고, 값이 음의 무한대로 갈수록 -1에 수렴한다.
옵티마이저
케라스에는 다양한 종류의 경사하강법 알고리즘을 제공하는데, 이것이 옵티마이저이다. 하이퍼파라미터임.
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')SGD 옵티마이저를 이용한 ex.
기본 경사하강법 옵티마이저 : SGD, 모멘텀, 네스테로프 모멘텀
적응적 학습률 옵티마이저 : RMSprop, Adam, Adagrad..
보통 Adam을 많이 사용한다.
6-3 신경망 모델 훈련
<tensorflow.python.keras.callbacks.History at 0x7fef38bfc080>노트북의 코드 셀은 print() 명령을 사용하지 않더라고 마지막 라인의 실행 결과를 자동으로 출력한다.
이 메시지는 fit() 메서드의 실행 결과를 출력한 것.
=> fit() 메서드가 History 클래스 객체를 반환한다.
- History 객체 : 훈련 과정에서 계산한 지표, 손실과 정확도 값이 저장되어 있어 이 값을 활용하면 그래프를 그릴 수 있다.
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)fit() 메서드의 결과를 history 변수에 담는다.
verbose : 훈련 과정 출력을 조정하는 매개변수. 1이 기본값임. 에포크마다 진행 막대와 함께 손실 등의 지표가 출력된다.
verbose가 2면 진행 막대를 빼고 출력하고, 0이면 훈련 과정을 나타내지 않는다는 의미이다.
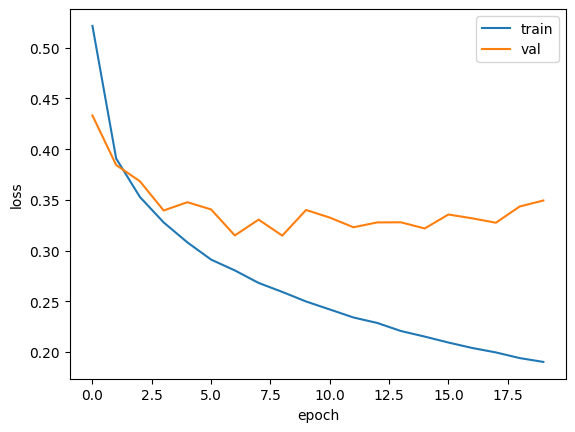
matplotlib로 history 딕셔너리에 있는 loss와 accuracy를 그래프로 그릴 수 있다.
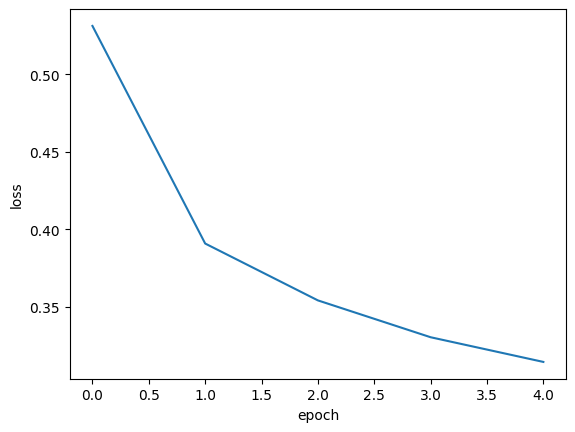
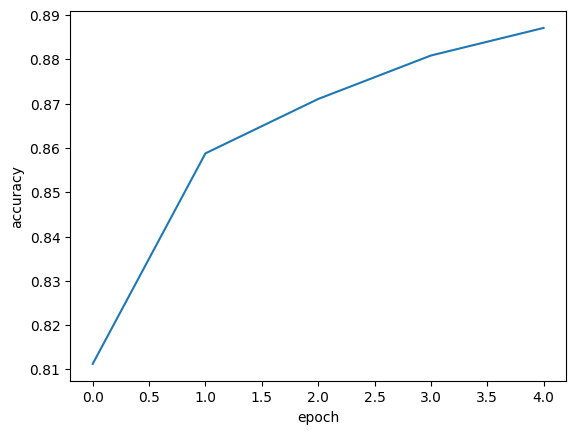
검증손실
에포크에 대한 과대적합과 과소적합을 파악하려면 훈련 세트에 대한 점수뿐만 아니라 검증 세트에 대한 점수도 필요하다.
# 에포크마다 검증 손실을 계산하기 위해 fit() 메서드에 검증 데이터를 전달한다.
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
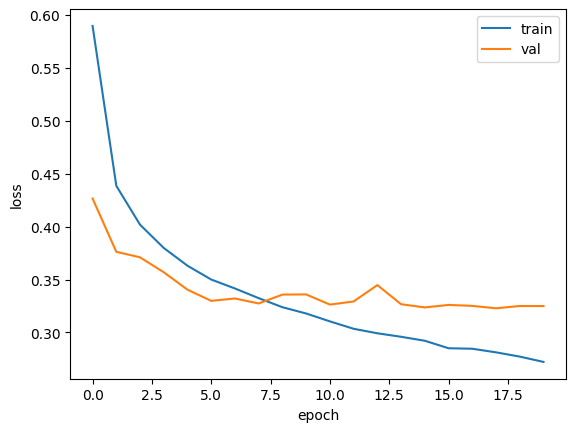
validation_data=(val_scaled, val_target))print(history.history.keys()) # history에 검증 세트에 대한 손실과 정확도 들어 있음을 확인함adam으로 적응적 학습률을 사용하여 학습률 크기를 조정한다 -> 과대적합이 이전보다 줄음을 확인할 수 있다.
드롭아웃
과대적합 막기 위해 규제 방법을 사용함.
- 드롭아웃 : 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서 ( 즉 뉴런의 출력을 0으로 만든다) 과대적합을 막는다.
- 얼마나 많은 뉴런을 드롭할건지 (percentage)는 또 다른 하이퍼파라미터가 된다.
- 드롭이 과대적합을 막는 이유 :
이전층의 일부 뉴런이 랜덤하게 꺼지면 특정 뉴런에 과대하게 의존하는 것을 줄일 수 있도 모든 입력에 대해 주의를 기울여야 한다.
일부 뉴런의 출력이 없을 수 있다는 것을 감안하면 이 신경망은 더 안정적인 예측을 만들 수 있다.
model = model_fn(keras.layers.Dropout(0.3))30% 의 뉴런을 끄는 dropout의 예시.
훈련이 끝난 뒤 평가나 예측을 할 때는 드롭아웃을 적용하지 말아야 한다. 훈련된 모든 뉴런을 사용해야 올바른 예측 가능. 텐서플로와 케라스는 모델을 평가와 예측에 사용할 때는 자동으로 드롭아웃을 적용하지 않는다.
모델 저장과 복원
model.save_weights('model-weights.h5') # save_weights() 메서드로 훈련된 모델의 파라미터를 저장할 수 있다. .h5 확장자일 경우 HDF5 포맷으로 저장함model.save('model-whole.h5') # 모델 구조와 모델 파라미터를 함께 저장하는 save() 메서드도 제공함. 기본적으로 SavedModel 포맷으로 저장하지만 .h5 확장자일 경우 HDF5 포맷 저장.모델의 가중치를 저장하여 나중에 불러와 사용할 수 있다.
'Group Study (2023-2024) > Machine Learning 입문' 카테고리의 다른 글
| [ML입문] week6 - 합성곱 신경망 (1) | 2023.12.23 |
|---|---|
| [ML입문] week6 - 순환 신경망 (1) | 2023.12.11 |
| [ML입문] week4 - 비지도 학습 (1) | 2023.11.27 |
| [ML입문] week3 - 분류 알고리즘(2), 트리 알고리즘 (0) | 2023.11.21 |
| [ML입문] week2 - 회귀 알고리즘과 모델 규제, 분류 알고리즘(1) (1) | 2023.11.13 |