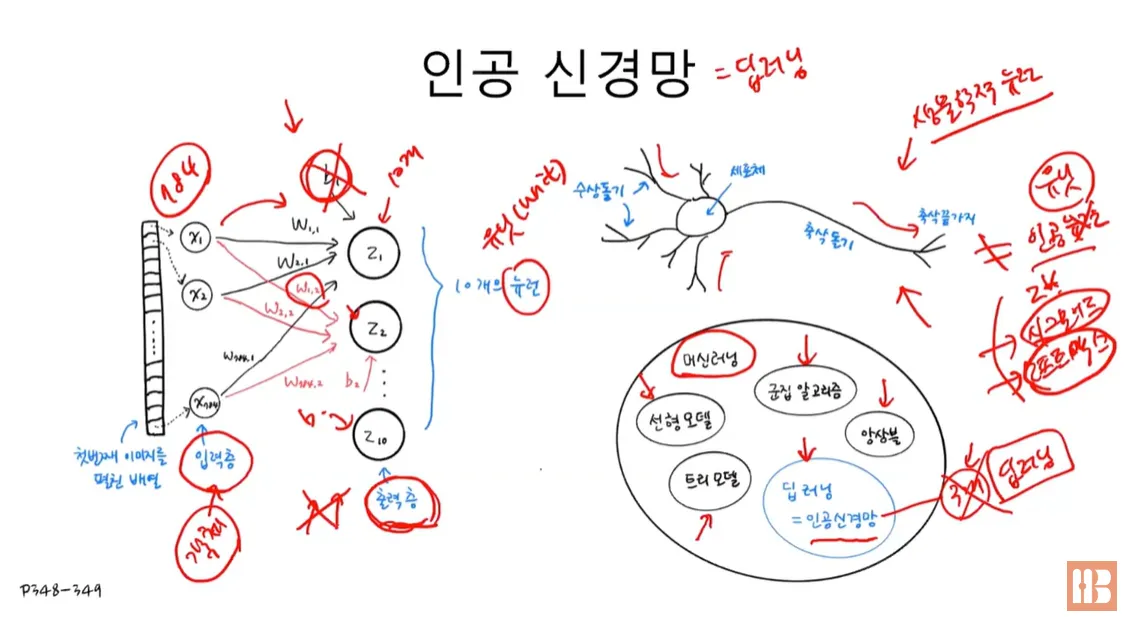
8. 텍스트를 위한 인공 신경망8.1. 순차 데이터와 순환 신경망8.1.1. 개요 - 용어 정리순차 데이터(Sequential data)순서에 의미가 있는 데이터예시텍스트 데이터 ⇒ 어순에 따라서 텍스트의 의미가 달라짐시계열 데이터(Time series data) ⇒ 온도 기록 데이터에서 시간 순서를 섞으면 다음 온도를 예상하기 어려움순환 신경망(Recurrent Neural Network, RNN)순환되는 고리가 있는 신경망앞의 샘플의 출력을 새로운 샘플을 계산할 때 재사용즉, 계산된 데이터는 이전 샘플에 대한 기억을 가지고 있다고 볼 수 있음입력에 가중치를 곱하고 활성화 함수를 통과시켜 다음 층으로 보내는 것은 다른 신경망과 동일하나, 층의 출력을 재사용하는 특징이 있는 신경망이러한 특징으로 순차 데..