Chapter03 회귀 알고리즘과 모델 규제
복습하기
Q. 도미와 빙어 구분하기(도미 : 1, 빙어 : 0)
A. K-최근접이웃 알고리즘을 사용
Problem : 잘못된 결과
Why : length보다 weight 특성이 결과에 더 큰 영향을 주게 됨
- X축(length) Scale : 10~40
- Y축(weight) Scale : 0~1000
Solution : 특성의 스케일을 맞추는 과정 즉, 데이터 전처리 과정이 필요
데이터 전처리 : 표준점수(Z점수, (특성 - 평균)/표준편차) 계산하기
- numpy의 mean(평균), std(표준편차) 함수 사용하여 Z점수 계산
- train data 전처리 방식으로 test data도 동일하게 전처리 진행
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
#Z점수 = train_scaled
train_scaled = (train_input - mean) / stdK-최근접 이웃 회귀
Q. 농어의 무게를 예측하기
target : 무게(임의의 수)
[지도학습 알고리즘]

- K-최근접 이웃 분류 : 가장 가까운 data들의 분류를 보고 결과값 도출
- K-최근접 이웃 회귀 : 가장 가까운 data들의 평균을 보고 결과값 도출
[Case1. 농어의 길이만 사용]
import matplotlib.pyplot as plt
#perch_weight : target data
plt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()Step01. 훈련 세트 준비
#훈련세트와 테스트세트 준비
from sklearn.model_selection import train_test_split
#회귀 문제에서는 클래스의 비율을 맞춰주는 stratify를 사용하지 않음
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state = 42)
#reshape : 행(-1) * 열(1) 인 2차원 배열 생성
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)Step02. 회귀 모델 훈련
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
#훈련 세트를 넣어 훈련하기
knr.fit(train_input, train_target)
#테스트 세트를 넣어 결정계수 확인
knr.score(test_input, test_target)
from sklearn.metrics import mean_absolute_error
#test_input으로 예측한 값
test_prediction = knr.predict(test_input)
#(타깃 - 예측) 절대값의 평균
mae = mean_absolute_error(test_target, test_prediction)
#약 9g의 오차 확인 가능
print(mae)과대적합? 과소적합?
- 과소적합(underfitting) : 훈련세트보다 테스트세트의 점수가 높을 경우
- 과대적합(overfitting) : 훈련세트에 너무 적합하여 테스트세트에서 결과값을 내지 못할 경우
Problem : 과소적합
Solution : 이웃의 개수를 줄이기
- 이웃의 개수가 적을 수록 과대적합을, 많을 수록 과소적합을 주의해야함
#이웃의 개수, 기본값 5를 3으로 줄이기
knr.n_neighbors = 3
knr.fit(train_input, train_target)
print(knr.score(train_input, train_target))
#0.9804899950518966
print(knr.score(test_input, test_target))
#0.9746459963987609
#score : 훈련 세트 > 테스트 세트 => 문제 해결선형 회귀
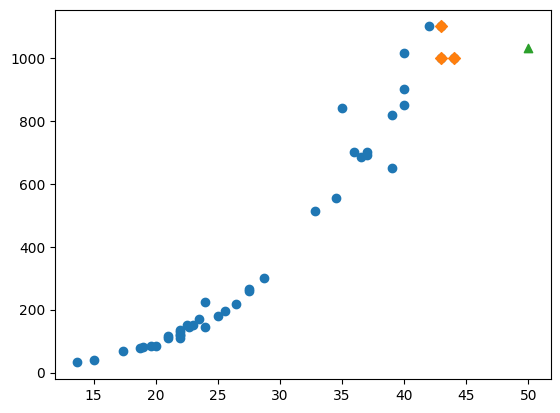
Problem : 아주 큰 길이의 농어 데이터가 들어간다면?
#50cm 농어의 이웃을 구하기
distances, indexes = knr.kneighbors([[50]])
#훈련 세트의 산점도 그리기
plt.scatter(train_input, train_target)
#훈련 세트 중에서 이웃 샘플만 다시 그리기
plt.scatter(train_input[indexes], train_target[indexes], marker = 'D')
#50cm 농어 데이터 표시
plt.scatter(50, 1033, marker = '^')
plt.show()
Solution : 선형회귀(linear regression)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
#선형 회귀 모델 훈련
lr.fit(train_input, train_target)
#50cm 농어에 대한 예측
print(lr.predict([[50]]))
#_ : 내가 넣은 데이터가 아닌 학습된 데이터
print(lr.coef_, lr.intercept_)
#훈련 세트의 산점도
plt.scatter(train_input, train_target)
#15에서 50까지 1차 방정식 그래프
plt.plot([15, 50], [15 * lr.coef_ + lr.intercept_, 50 * lr.coef_ + lr.intercept_])
#50cm 농어 데이터
plt.scatter(50, 1241.8, marker='^')
plt.show()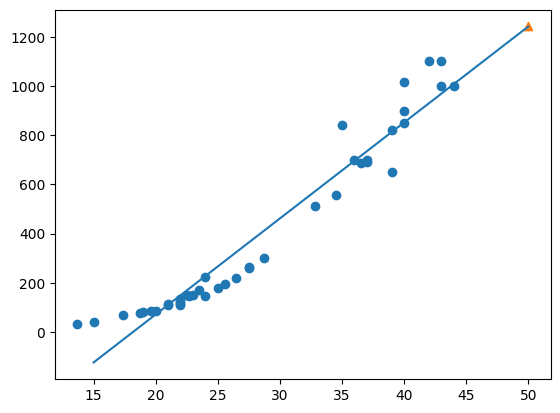
- 다항회귀
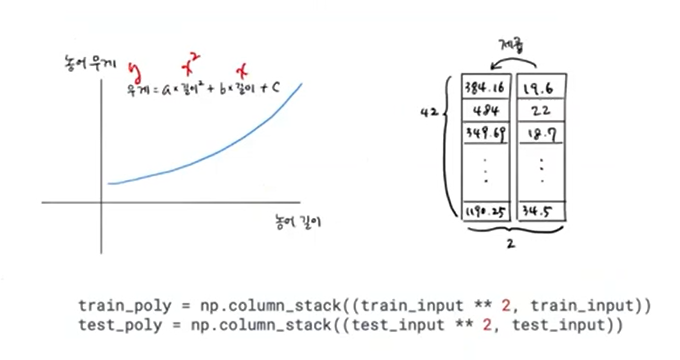
#제곱 특성 추가!!
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))
#다항회귀 모델 훈련
lr.fit(train_poly, train_target)
print(lr.predict([[50 ** 2, 50]]))
#[1573.98423528]
print(lr.coef_, lr.intercept_)
#[ 1.01433211 -21.55792498] 116.0502107827827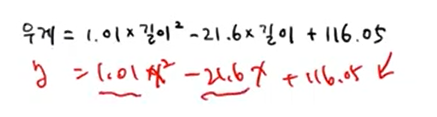
#구간별 직선을 그리기 위해 15 ~ 49 정수 배열 생성
point = np.arange(15, 50)
#훈련 세트의 산점도
plt.scatter(train_input, train_target)
#15 ~ 49 2차 방정식 그래프 그리기
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
#50cm 농어 데이터
plt.scatter([50], [1574], marker = '^')
plt.show()
#score 확인
print(lr.score(train_poly, train_target))
#0.9706807451768623
print(lr.score(test_poly, test_target))
#0.9775935108325122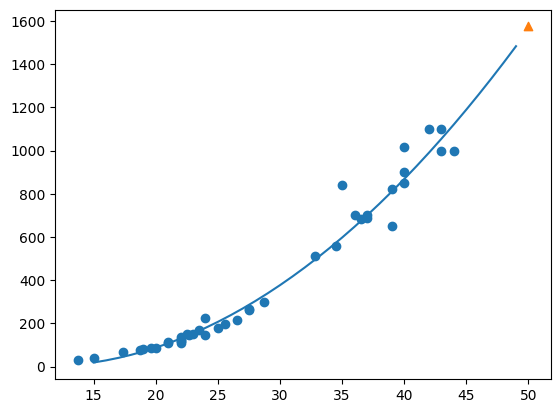
특성 공학과 규제
- 다중 회귀(multiple regression)
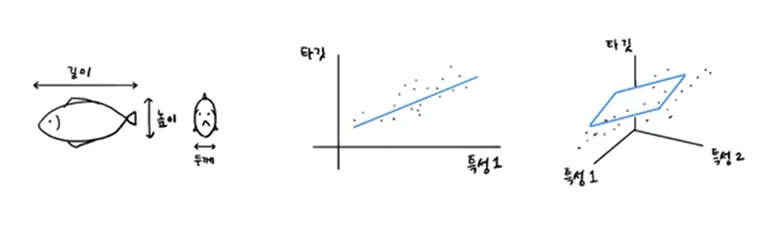
[Case2. 다항 특성 사용 ]
#판다스로 데이터 준비
import pandas as pd
df = pd.read_csv('https://bit.ly/perch_csv')
perch_full = df.to_numpy()
print(perch_full)Step01. 다항 특성 만들기
from sklearn.preprocessing import PolynomialFeatures
#기본값 degree = 2, include_bias = True)
poly = PolynomialFeatures(degree = 5, include_bias = False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
test_poly = poly.transform(test_input)
print(train_poly.shape)
#!!!!!!!!!!(42, 55) => (42, 5) 강의랑 다른 값
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))Problem : 과대적합 발생
Solution : 규제
#규제를 가하기 전 표준화 하기
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)
규제가 적용된 선형모델1 : Ridge
#규제가 적용된 선형모델1 : Ridge
from sklearn.linear_model import Ridge
#Ridge(alpha = 1) : 규제의 정도
ridge = Ridge()
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
print(ridge.score(test_scaled, test_target))
+) 적절한 규제의 강도 찾기 : alpha 값 찾기
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
train_score = []
test_score = []
for alpha in alpha_list :
#ridge model 만들기
ridge = Ridge(alpha = alpha)
#ridge model 훈련
ridge.fit(train_scaled, train_target)
#훈련 점수와 테스트 점수 저장
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R^2')
plt.show()- Lasso의 특징 : 특성 가중치를 0으로 만들어 특정 특성 배제 가능
참고자료 : '혼자 공부하는 머신러닝 딥러닝' 인프런 강의
'Group Study (2024-2025 Q1) > Machine Learning 입문' 카테고리의 다른 글
| [ML 입문] 6주차 스터디 (3) | 2024.11.10 |
|---|---|
| [ML 입문] 5주차 스터디 (1) | 2024.11.06 |
| [ML 입문] 4주차 스터디 (0) | 2024.10.30 |
| [ML 입문] 3주차 스터디 (1) | 2024.10.16 |
| [ML 입문] 1주차 스터디 (0) | 2024.10.02 |