5-1. 로지스틱 회귀로 와인 분류하기
0. 개요
- 결정 트리: 예, 아니오에 대한 질문을 이어나가며 정답을 찾아 학습하는 알고리즘
- 불순도: 결정 트리가 최적의 질문을 하기 위한 기준. 사이킷런에서 지니 불순도와 엔트로피 불순도 제공
데이터 준비
- 훈련세트와 테스트세트로 나눈 뒤 전처리
- 두 세트 모두 적용되는 전처리 방식이 같다
import pandas as pd
wine = pd.read_csv('<https://bit.ly/wine_csv_data>')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
- 누락된 데이터가 있는지 확인하는 info() 함수
wine.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6497 entries, 0 to 6496
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 6497 non-null float64
1 sugar 6497 non-null float64
2 pH 6497 non-null float64
3 class 6497 non-null float64
dtypes: float64(4)
memory usage: 203.2 KB
1. 와인 분류하기
1-1. 로지스틱 회귀 적용
- 로지스틱 회귀를 적용하여 얻은 데이터로 어떤 값이 어떤 영향을 끼치는지 추측 가능
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
# 로지스틱 회귀 적용
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target)) # 0.7808350971714451
print(lr.score(test_scaled, test_target)) # 0.7776923076923077
1-2. 결정 트리 적용
- 직관적 (예/아니오로 분류)
- maxfeatures의 수 지정 시 지정된 수만큼만 사용
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
#0.996921300750433
print(dt.score(test_scaled, test_target))
#0.8592307692307692
- 시각화 (트리 깊이 제한 없음)
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# 그래프사이즈 설정, 가로 세로 inch기준
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()

- 시각화 (노드)
- max_depth로 트리 깊이 제한
- filled로 클래스에 맞게 노드 색 지정
- features_names로 특성의 이름 전달
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()

1-3. 지니 불순도
- gini (지니 불순도)
- gini는 DecisionTreeClassifier 클래스의 criterion 매개 변수의 기본값
- criterion의 매개 변수가 entrophy일 경우 → 엔트로피 불순도 사용
- 자식 노드의 불순도를 샘플 개수에 비례하여 모두 더한 후 부모 노드의 불순도를 빼면 된다
- 지니 불순도 = 0일 경우 순수 노드
- 위 그림에서의 불순도 차이
부모의 불순도 - (왼쪽노드 샘플 수 / 부모의 샘플 수) * 왼쪽 노드 불순도 - (오른쪽노드 샘플 수 / 부모의 샘플 수) * 오른쪽 노드 불순도
- 정보 이득 : 부모와 자식 노드 사이의 불순도 차이
1-4. 가지치기 하기
- 간단한 방법 = 트리의 최대 깊이 지정
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target) # 전처리하지 않은 데이터
print(dt.score(train_scaled, train_target)) # 0.8454877814123533
print(dt.score(test_scaled, test_target)) # 0.8415384615384616
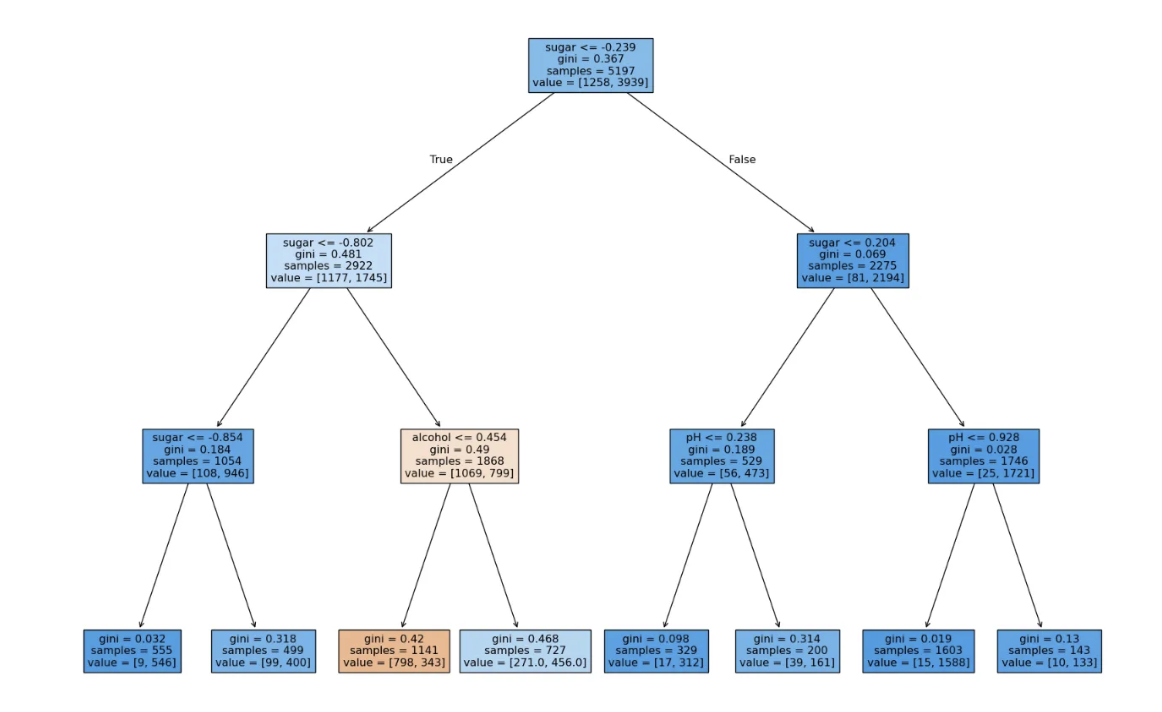
- 시각화
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
5-2. 교차 검증과 그리드 서치
0. 개요
- 일반화 성능의 올바른 예측을 위해 검증 세트, 교차 검증, 그리드 서치와 랜덤 서치 활용 → 하이퍼 파라미터 튜닝
1. 검증 세트
1-1. 데이터 준비
import pandas as pd
wine = pd.read_csv("<http://bit.ly/wine_csv_data>")
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
1-2. 훈련/테스트/검증 세트 나누기
- test_size 매개변수를 0.2로 정함
- 훈련세트의 20%를 검증 세트로 만듦
- 데이터가 많을 수록 좋음
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
sub_input, val_input, sub_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)
1-3. 검증세트로 모델 평가
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target)) # 0.9971133028626413
print(dt.score(val_input, val_target)) # 0.864423076923077
2. 교차 검증
- 검증 세트 만들 경우 훈련 세트가 줄어든다 ↔ 검증 세트를 조금 만들면 검증 점수가 불안정
- ⇒ 교차 검증 사용시 안정적 점수 + 훈련에 많은 데이터 사용 둘 다 가능
- k-폴드 교차 검증: 훈련 세트를 k개의 부분으로 나누어 교차 검증 수행
- cross_validate() 교차 검증 함수 사용
- 기본적으로 5개의 폴드
- scores는 fit_time, score_time, test_score 키를 가진 딕셔너리 반환
- test_score 키에 담긴 값 출력해서 교차 검증 최종 점수 확인
- test_score에는 5개의 점수 평균값
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
import numpy as np
print(np.mean(scores['test_score'])) # 0.855300214703487
- 교차 검증에서 훈련 세트를 섞고자 할 때 분할기 이용
- cross_validate()가 회귀 모델일 경우 → KFold 분할기
- cross_validate()가 분류 모델일 경우 → StratifiedKFold
from sklearn.model_selection import StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score'])) # 0.855300214703487
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score'])) # 0.8574181117533719
3. 하이퍼파라미터 튜닝
- 하이퍼 파라미터: 머신러닝 모델이 파라미터를 학습할 수 없어 사용자가 지정해야하는 파라미터
- 사이킷런에서 그리드 서치 제공
3-1. 그리드 서치
- 사이킷런의 GridSearchCv는 하이퍼파라미터 탐색과 교차 검증 한번에 수행
- min_impurity_decrease 매개변수의 최적값을 찾아보자
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
# 모델과 파라미터와 사용할 CPU 코어 개수 전달 (전부 사용)
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
# 총 25번 계산 (cv 매개변수 기본값 = 5, 5 폴드 교차 검증 수행)
gs.fit(train_input, train_target)
# 최적의 매개변수는 best_params_에 저장
# 각 매개변수에서의 교차검증의 평균점수는 cv_result_속성의 mean_test_score에 저장
print(gs.best_params_) # {'min_impurity_decrease': 0.0001}
print(gs.cv_results_['mean_test_score']) # [0.86819297 0.86453617 0.86492226 0.86780891 0.86761605]
- 더 복잡한 매개변수 조합 탐색
- 교차 검증 횟수 = 9 * 15 * 10 = 1350
- 만들어지는 모델 = 6750 (5 폴드 교차 검증 수행)
params = {'min_impurity_decrease' : np.arange(0.0001, 0.001, 0.0001),
'max_depth' : range(5,20,1),
'min_samples_split' : range(2,100,10)
}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
print(gs.best_params_) # {'max_depth': 14, 'min_impurity_decrease': 0.0004, 'min_samples_split': 12}
# 최상의 교차 점수
print(np.max(gs.cv_results_['mean_test_score'])) # 0.8683865773302731
3-2. 랜덤 서치
- 매개 변수 값이 수치 || 값의 범위나 간격을 미리 정하기 어려움 || 너무 많은 매개변수 조건 때문에 그리드 서치 오래걸림 ⇒ 랜덤 서치 추천
- 매개 변수를 샘플링 할 수 있는 확률 분포 객체를 전달
# uniform(), randint()로 실수값과 정수값을 샘플링
from scipy.stats import uniform, randint
from sklearn.model_selection import RandomizedSearchCV
params = {'min_impurity_decrease' : uniform(0.0001, 0.001), #실수
'max_depth' : randint(20, 50), #정수
'min_samples_split' : randint(2, 25),
'min_samples_leaf' : randint(1, 25),
}
- n_iter 매개변수로 샘플링 횟수를 지정
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
print(gs.best_params_) # {'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173, 'min_samples_leaf': 7, 'min_samples_split': 13}
print(np.max(gs.cv_results_['mean_test_score'])) # 0.8695428296438884
- 최적의 모델로 테스트 세트의 성능 확인
dt = gs.best_estimator_
print(dt.score(test_input, test_target)) # 0.86
5-3. 트리의 앙상블
0. 개요
앙상블 학습: 더 좋은 예측 결과를 만들기 위해 여러개의 모델을 훈련하는 머신 러닝 알고리즘
- 정형 데이터를 다루는데 좋음
- 정형 데이터: 어떤 구조로 된 데이터
- DB에 저장하기 쉽다
- 비정형 데이터에는 신경망 알고리즘이 좋음 (딥러닝)
- 결정 트리 기반으로 만들어져 있음
1. 랜덤 포레스트
- 랜덤 포레스트: 결정 트리를 랜덤하게 만들어 결정 트리의 숲을 만듦 → 각 결정 트리의 예측을 사용해 최종 예측을 만듦
- 각 트리 훈련을 위한 데이터를 랜덤하게 만든다
- 입력된 훈련 데이터에서 랜덤하게 샘플 추출하여 훈련 데이터를 만든다 (중복되게 샘플 뽑을 수 있음 → 부트 스트랩 샘플)
- 부트 스트랩 샘플: 중복을 허용한 샘플
- RandomForestClassifier (분류 모델): 전체 특성 개수의 제곱근만큼의 특성 선택
- RandomForestRegressor (회귀 모델): 전체 특성 사용
- 사이킷런의 랜덤 포레스트는 100개의 결정트리를 기본적으로 훈련
- 분류일 경우: 가장 높은 확률을 가진 클래스를 예측으로 삼는다
- 회귀일 경우: 각 트리의 예측을 평균화
1-1. 랜덤 포레스트 적용 @ 분류모델
- csv 파일을 numpy 배열로 변환 → 훈련세트와 테스트세트로 나눔
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv("<https://bit.ly/wine_csv_data>")
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(data, target, random_state=42, test_size=0.2)
- RandomForestClassifier 클래스로 모델을 만든 후, cross_validate()로 교차 검증 수행
from sklearn.model_selection import cross_validate #교차 검증
from sklearn.ensemble import RandomForestClassifier #랜덤포레스트 분류모델
# 랜덤포레스트 객체 생성
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
# return_train_score로 훈련세트 점수도 같이 반환 / 기본값 false / 5폴드 교차검증
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score'])) # 0.9973541965122431 0.8905151032797809
→ 훈련세트 점수 > 검증세트 점수
⇒ 과대적합
- 특정 중요도 출력 가능
rf.fit(train_input, train_target)
# 도수, 당도, pH
print(rf.feature_importances_) # [0.23167441 0.50039841 0.26792718]
- Out Of Bag (OOB) 샘플: 부트스트랩 샘플에 포함되지 않고 남는 샘플
- 검증 세트 역할 가능
- oob_score=True로 지정해서 사용
- OOB 점수 사용 시 교차 검증을 대신할 수 있음 → 훈련 세트에 더 많은 샘플 사용 가능
rf = RandomForestClassifier(n_jobs=-1, oob_score=True, random_state=42)
rf.fit(train_input, train_target)
rf.oob_score_ # 0.8934000384837406
2. 엑스트라 트리
엑스트라 트리: 위와 마찬가지로 100개의 결정 트리를 훈련 but 랜덤포레스트와 다르게 부트스트랩 샘플을 사용하지 않음
- 결정 트리 만들 때 전체 훈련 세트 사용
- 노드 분할 시 무작위 분할 (가장 좋은 부분을 찾지 않음)
- DecisionTreeClassifier의 splitter 매개변수를 random으로 지정해서 사용할 수도 있음
2-1. 엑스트라 트리 적용
- 사이킷런의 엑스트라 트리: ExtraTreesClassifier
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score'])) # 0.9974503966084433 0.8887848893166506
- 무작위성이 더 크기에 더 많은 결정트리를 훈련해야하나 랜덤하게 노드를 분할하기에 빠른 계산 가능
3. 그레이디언트 부스팅
그레이디언트 부스팅: 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식으로 앙상블하는 방법
- 사이킷런의 GradientBoostingClassifier: 기본적으로 깊이가 3인 결정 트리 100개 사용
- 깊이가 앝은 결정 트리 사용 → 과대적합에 강하고 높은 일반화 성능 기대 가능
- 경사 하강법 사용하여 앙상블에 트리 추가
- 분류 모델일 경우: 로지스틱 손실 함수 사용
- 회귀 모델일 경우: 평균 제곱 오차 함수 사용
3-1. 그레디언트 부스팅 적용
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1) # 훈련세트, 교차검증
print(np.mean(scores['train_score']), np.mean(scores['test_score'])) # 0.8881086892152563 0.8720430147331015
- 위 교차 검증 결과를 통해 과대 적합에 강하다는 것을 확인
- n_estimators (결정트리 개수) learning_rate (학습률, 기본값 0.1)를 증가시키면 성능 향상 가능
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2 ,random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score'])) # 0.9464595437171814 0.8780082549788999
4. 히스토그램 기반 그레이디언트 부스팅
히스토그램 기반 그레이디언트 부스팅: 정형 데이터를 다루는 머신러닝 알고리즘 중 인기짱
- 입력 특성을 256개의 구간으로 나눔
- 누락된 특성 전처리 필요 없음
4-1. 히스토그램 기반 그레이디언트 부스팅 적용
- 성능을 높이려면 max_iter 매개변수 이용
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target, return_train_score=True)
print(np.mean(scores['train_score']), np.mean(scores['test_score'])) # 0.9321723946453317 0.8801241948619236
- 위 결과를 토대로 과대적합을 억제하며 그레이디언트 부스팅보다 조금 더 높은 성능을 제공함을 확인
- permutation_importance()함수로 특성 중요도를 계산
- n_repeats 매개변수로 랜덤하게 섞을 횟수 지정 가능 (기본값 5)
from sklearn.inspection import permutation_importance
hgb.fit(train_input, train_target)
#특성 중요도, 평균, 표준편차 반환
#훈련세트 특성 중요도
result1= permutation_importance(hgb, train_input, train_target, n_repeats=10, random_state=42, n_jobs=-1)
print(result1.importances_mean) # [0.08876275 0.23438522 0.08027708]
#테스트세트 특성 중요도
result2= permutation_importance(hgb, test_input, test_target, n_repeats=10, random_state=42, n_jobs=-1)
print(result2.importances_mean) # [0.05969231 0.20238462 0.049 ]
print(hgb.score(test_input, test_target)) # 0.8723076923076923
- 위 결과를 토대로 당도에 조금 더 집중함을 확인 가능
4-2. XGBoost
- 사이킷런의 cross_validate()와 같이 사용 가능
- tree_method 매개변수를 hist로 지정 시 히스토그램 기반 그레이디언트 부스팅을 사용 가능
from xgboost import XGBClassifier
xgb = XGBClassifier(tree_method='hist', random_state=42)
scores = cross_validate(xgb, train_input, train_target, return_train_score=True)
print(np.mean(scores['train_score']), np.mean(scores['test_score'])) # 0.8824322471423747 0.8726214185237284
4-3. LightGBM
- cross_validate()와 같이 사용 가능
from lightgbm import LGBMClassifier
lgb = LGBMClassifier(random_state=42)
scores = cross_validate(lgb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score'])) # 0.9338079582727165 0.8789710890649293
from lightgbm import LGBMClassifier
lgb = LGBMClassifier(random_state=42)
scores = cross_validate(lgb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score'])) # 0.9338079582727165 0.8789710890649293
'Group Study (2024-2025) > Machine Learning 입문' 카테고리의 다른 글
| [ML 입문] 6주차 스터디 (3) | 2024.11.10 |
|---|---|
| [ML 입문] 5주차 스터디 (1) | 2024.11.06 |
| [ML 입문] 3주차 스터디 (1) | 2024.10.16 |
| [ML 입문] 2주차 스터디 (0) | 2024.10.07 |
| [ML 입문] 1주차 스터디 (0) | 2024.10.02 |