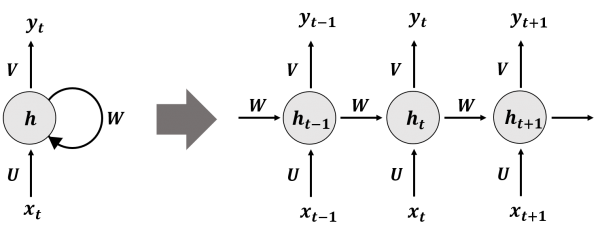
1. 합성곱 신경망 합성곱 신경망은 주로 이미지 분류를 할 때 자주 쓰이는 신경망이다. 이러한 합성곱 신경망은 크게 합성곱층과 풀링층의 쌍으로 구성된다. 2. 합성곱층 2-1 ) 연산 과정 합성곱층에서는 합성곱 연산을 통해 이미지의 특징을 추출한다. 3x3 또는 5x5 크기의 행렬인 필터(커널)를 이미지의 왼쪽 위부터 오른쪽 아래까지 순차적으로 훑는다. 이렇게 훑는 과정을 슬라이딩이라고 한다. 위 사진에서는 5x5 크기의 이미지를 3x3 커널을 슬라이딩 시켰다. 총 행 방향 2번, 열 방향 2번의 슬라이딩을 통해 2x2 크기의 행렬을 얻었다. 커널을 사용하여 합성곱 연산을 통해 나온 결과값을 특성 맵이라고 한다. 또한, 이처럼 합성곱 연산을 통해 얻은 특성 맵의 크기는 이미지의 크기보다 작다. 2-2 )..