
1. GAN 이란?
2014년 이안 굿펠로우(Ian Goodfellow)에 의해 발표된 개념으로, Generative Adversarial Network의 약자입니다.
1-1 'Generative' - 생성 모델
Generative 라는 말에서 알 수 있듯이 이는 생성 모델로 그럴듯한 가짜 이미지를 만들어내는 모델입니다. 여기서 그럴듯 하다는건 수학적으로 실제 데이터의 분포와 비슷한 분포에서 나온 데이터를 의미합니다.
GAN의 학습 과정을 보면 이렇게 점차 실제 데이터의 분포에 근사해 나가는 것을 볼 수 있습니다.
1-2 'Adversarial' - 적대적 생성
두번째 단어 Adversarial은 적대적이라는 뜻으로 두 개의 모델이 적대적으로 경쟁하며 발전한다는 의미입니다. 이를 설명하기 위해 흔히 사용되는 예시가 바로 위조지폐범과 경찰입니다.
이 둘은 적대적인 경쟁 관계로,
위조지폐범은 경찰을 속이기 위해 점점 위조 기술을 발전시키고
경찰은 위조지폐범을 잡기 위해 점점 위조 지폐를 찾는 기술을 발전시킵니다.
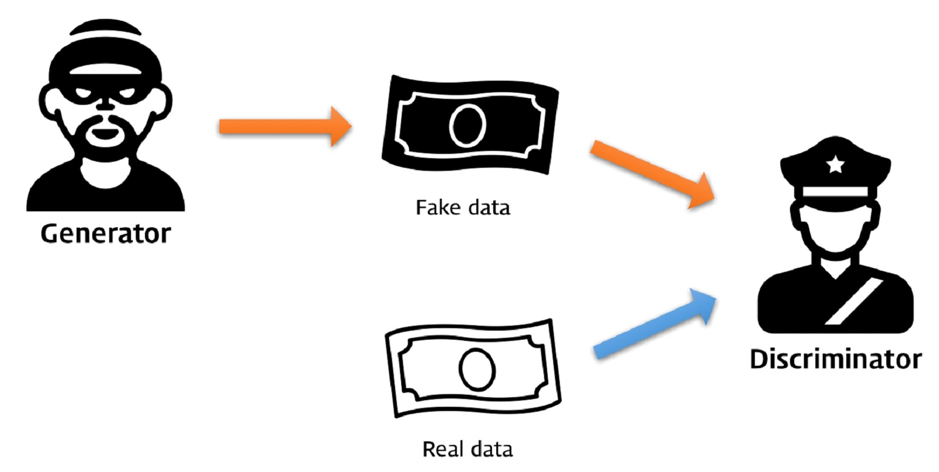
GAN에는 위조지폐범에 해당하는 생성자(Generator)와 경찰에 해당하는 판별자(Discriminator)가 있어 이 둘이 경쟁적 학습을 합니다.
생성자(Generator)의 목적은 그럴듯한 가짜 데이터를 만들어서 판별자(Discriminator)를 속이는 것이고, 판별자(Discriminator)의 목적은 생성자(Generator)가 만든 가짜 데이터와 진짜 데이터를 구분하는 것입니다. 이 둘을 함께 학습시키면서 진짜와 구분할 수 없는 가짜를 만들어 낼 수 있게 됩니다.
1-3 'random vector z'
처음에 생성자(Generator)가 이미지를 생성할 때는 어떤 분포로부터 샘플링한 random vector z를 input으로 합니다.
2. DCGAN (Deep Convolutional GAN)
DCGAN은 2015년에 발표된 논문으로, 이후 2년만에 1000회 이상 인용이 되었을 정도로 유명하고 중요한 논문입니다.
원래 GAN의 구조는 단순히 Fully-connected로 연결되어 있는데
DCGAN은 GAN에 *CNN 구조를 적용하고 최적의 결과를 내기 위해 실험을 통해 다양한 방법들을 적용한 최적의 구조를 찾아냈습니다. 이를 통해 더 안정적으로 학습하고 더 향상된 결과를 볼 수 있었습니다.
*CNN - Convolutional Neural Networks의 약자로 딥러닝에서 주로 이미지나 영상 데이터를 처리할 때 쓰이는 인공 신경망의 한 종류
여기서, 앞서 설명한 vector z를 이용한 산술적 연산이 가능하다는 것을 보여줍니다. 이는 학습이 제대로 이루어지면 z값이 의미 있는 값을 가지게 된다는 것 입니다.
3. GAN의 발전
GAN은 2014년 이후 지금까지 정말 다양하게 발전되어 왔고, GAN, DCGAN, WGAN, CycleGAN, StyleGAN 등등 다 나열할 수 없을 정도로 많은 논문들이 현재까지도 나오고 있습니다. 위의 그래프만 봐도 정말 폭발적으로 관련한 연구가 증가하고 있음을 볼 수 있습니다. 이렇게 계속 발전되어 현재는 처음 보여드린 StyleGAN으로 생성된 이미지처럼 정말 구분되지 않을 정도의 이미지를 생성하는 수준에 이르렀습니다.
4. GAN Applications
Facial attribute transfer
Font generation
Anime character generation
Photos to Emojis
Image Inpainting
Super Resolution
Human pose estimation
Image to Image
Text to Image
마지막으로... 최근에 봤던 놀라운 결과....
'GDSC Sookmyung 활동 > 10 min Seminar' 카테고리의 다른 글
| 파이썬으로 웹 스크래핑 시작하기 (0) | 2021.02.23 |
|---|---|
| 사람의 지도 없이 학습하는 오토인코더 (1) | 2021.02.21 |
| Yolact로 이미지 딥러닝하기 (0) | 2021.02.15 |
| TCP&UDP (0) | 2021.01.30 |
| Flutter 소개와 Firebase 연동 (0) | 2021.01.24 |