Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition
computer vision
: 컴퓨터로 시각데이터를 처리하는 분야
=> 사람과 컴퓨터가 받아들이는 것은 다르기에 시각적데이터의 내용을 자동으로 이해하고 분석할 수 있는 기술을 개발하는 것이 중요!
컴퓨터비전은 다양한 분야에서의 능력이 필요함 (물리학, 생물학, 생리학, 수학, 공학...)
비전의 역사
1. 시력 앤드류파커, 최초의 동물은 눈을 발달시켰고 시력이 발달되며 폭발적인 종분화 단계가 시작. 진화의 빅뱅 시작이 5억 4천만년후에 동물의 시각에서 시작 - 시각의 중요성 : 지능이 높은 인간의 가장 큰 감각시스템으로 발전. 시각처리에 관여하는 피질 뉴런의 거의 50%가 시각처리에 관여함
2. 초기 카메라 르네상스 시대 1600년대의 카메라 Obscura : 핀홀 카메라 이론을 기반으로 한 카메라 - 유사성 : 빛을 모으는 구멍 = 정보를 모음 , 이미지를 투사하는 카메라 뒷면의 평면 = 동물이 발달한 초기 눈
컴퓨터비전의 역사
1960년대
1959년, Hubel, Wiesel 연구 : ‘영장류나 포유류의 시각 처리 메커니즘은 어떠했는가’
연구내용 : 시각처리관점에서 인간의 뇌와 유사한 고양이의 뇌를 연구 일차 시각 피질 영역이 있는 고양이의 뇌 뒤쪽에 전극 몇개를 부착한 다음 어떤 자극이 고양이의 뇌의 일차 시각 피질 뒤쪽에 있는 뉴런을 흥분하게 만드는지 살핌
결론 : 가장 중요한 세포 중 하나는 특정 방향으로 움직일때 방향이 지정된 가장자리에 반응하는 단순세포였음
⇒ 대체로 시각적 처리가 시각적세계의 단순한 구조(지향적인 가장자리)에서 시작되고 정보가 시각적 처리 경로를 이동함에 따라 뇌는 시각적 정보의 복잡성을 구축
1963년, Block World : Larry Roberts의 출판 작품
시각적 세계를 기하학적 모양으로 단순화하고 인식. 모양의 재구성
1966년, MIT : The summer vision project
프로젝트의 목표 : 시각 시스템의 중요한 부분을 구축해보자!
1970년대, 1980년대
1970년, David Marr : 비전이 무엇인지, 컴퓨터 비전과 컴퓨터가 시각적 세계를 인식할 수 있는 알고리즘을 개발하는 방법에 대해 영향력있는 책을 작성
60, 70, 80년대 컴퓨터 비전의 과제가 무엇인지에 대한 고민을 함. 객체인식 문제를 해결하는 것은 어려웠음. 실제 세계에서의 측면에서는 진전이 이루어지지 않음
1990년대, 2000년대
1997년, Shi & Malik : Normalized Cut
앞선 객체인식 문제해결의 어려움을 토대로...
이미지를 가져와 픽셀을 의미 있는 영역으로 그룹화하는 작업을 진행함
-> 함께 그룹화된 픽셀이 사람이라고 불리는지는 알수없지만 사람에 속한 모든 픽셀을 추출할 순 있음
2001년, Viola & Jones : Face Detection (얼굴인식)
adaboost 알고리즘을 사용해 실시간 얼굴 감지를 수행함.
컴퓨터 칩이 느림에도 거의 실시간으로 이미지의 얼굴인식이 수행됨.
5년만에 실시간 얼굴 탐지기가 있는 카메라를 출시함
1999년, David Lowe : "sift", Object Recognition
배경 : 시점, 조명 등의 본질적인 변화로 인해 모든 종류의 변화가 생길 수 있기에 (예를들어 다른 두 정지신호를 일치시키는 것이 매우 어려움) -> 불변하는 경향이 있는 객체의 일부 특징을 관찰
객체인식 작업 : 객체의 중요한 특징을 식별하고 다음 특징을 일치시킴
2006년, Lazebnik, Schmid, Ponce : Spatial Pyramid Matching
Spatial pyramid matching 알고리즘 : 특징을 잘 뽑아낼 수 있다면 이미지의 특징이 어떤 유형의 장면인지에 대한 단서를 제공해줄 수 있다는 것
이미지 내의 여러 부분과 해상도에서 추출한 특징을 하나의 특징 기술자로 표현하고 알고리즘을 적용
2005년, 2009년, Dala & Triggs : Histogram of Gradients / Felzenswalb, McAllester, Ramanan : Deformable Part Model
특징을 조합해 사실적인 이미지로 인체를 구성하고 인식할 수 있는 방법을 살펴보는 작업을 함
2006-2012년, PASCAL VOC(visual object challenge)
배경 : 2000년대초, 컴퓨터비전분야의 중요한 ‘구성요소문제’를 정의하게됨 (객체 인식기술이 얼마나 발전되었는가 확인하기위해 benchmark dataset을 모으기 시작)
pascal visual object challenge : 20개의 객체클래스로 구성되며 카테고리당 수천~만개의 이미지로 구성된 데이터셋을 가지고, 다양한 연구집단에서는 자신들의 알고리즘을 테스트해봄
<- 년도를 거듭할수록 성능이 계속해서 향상하는 것을 볼 수 있음
2009년, ImageNet
배경 : 시각데이터가 너무 복잡해 많은 파라미터가 필요함. 학습데이터가 부족하면 과적합이 빠르게 발생하고 일반화능력이 떨어짐 1. 모든 객체를 인식하고 싶다 + 2. 기계학습의 과적합 문제를 해결하고싶다 => ImageNet프로젝트 시작
진행방식 : 구할 수 있는 모든 사진 데이터셋을 모아 훈련하고자 함. 3년동안 인터넷에서 수십억장의 이미지를 다운받고, wordnet(수천가지의 객체클래스)이라는 딕셔너리로 정리함. Amazon mechanical turk에서 사용하는 이미지 정렬, 정제, 레이블을 제공하는 플랫폼인 clever crowd engineering trick을 도입
imagenet : 당시 가장 큰 데이터 셋으로 약 15만장에 달하는 이미지와 22만가지의 클래스 카테고리를 보유
2009년, ILSVRC를 주최 : 1000개의 객체에서 140만개의 testset이미지를 엄선함. 이미지 분류문제를 푸는 알고리즘들을 테스트
그래프 x축 : 연도, y축 : 오류율 / 객체인식의 모든 문제를 해결하진 못했지만 계속해서 오류율은 감소함
특히, 2012년에 CNN(convolution neural network)를 도입하므로써 오류율이 급격히 감소하고 발전에 가속을 더하게됨
Lecture 2 | Image Classification
Image Classification
: 이미지 내용을 기반으로 이미지를 분류하고 레이블을 지정하는 과정
어려운 점
컴퓨터는 이미지를 픽셀값인 숫자로 인식하기에 실제 의미하는 것과의 격차가 발생(의미적 격차)
조그만한 변화에도 픽셀의 격자는 완전히 바뀜 (ft. 조명, 물체의 변형, 일부만 보임, 배경혼란, 클래스의 다양성 등)
시도
1. 이미지 인식에서 명확한 알고리즘을 작성하기 위한 시도
정렬 등 문제에서는 간단하고 명확한 알고리즘이 있지만 이미지 인식에는 없기에 사람들은 다양한 동물을 인식하기위한 일종의 고급코드규칙을 작성하려는 명시적인 시도들을 해왔음
이미지의 가장자리를 계산한 후 모서리와 경계를 각 카테고리별로 분류 ex_ 세개의 선이 만나는 지점이 모서리라할때, 귀는 여기와 저기에 모서리가 위치함 → 사물을 인식하기위해 ‘명시적인 규칙집합’을 써내려가는 방법
한계 : 강인하지 못한 알고리즘. 계속해서 달라지는 객체에대해 계속 새로운 알고리즘을 작성해야됨
2. 데이터 기반 접근방식
이미지와 클래스 데이터들을 바탕으로 모델을 학습해 분류 성능을 평가하는 방식
train함수 : 이미지와 레이블(클래스)을 입력으로 받고, 모델을 출력 predict함수 : 모델을 입력으로 받고, 이미지에 대한 예측을 수행
NN(Nearest Neighbor)
: 새로운 이미지가 들어오면 기존의 학습데이터와 비교해서 가장 유사한 이미지의 라벨을 예측하는 방법
L1거리공식을 이용해 테스트이미지와 훈련예제를 비교하고 훈련세트에서 가장 유사한 예제를 찾음
<시간복잡도> train : O(1), 데이터를 기억만 하기에 predict : O(N), 데이터세트의 n개 훈련예제를 각각 비교 → 훈련시간 > 테스트시간
=> 모든 사진의 픽셀값을 계산하기에 예측 과정에서 소요되는 시간이 상당하다는 한계가 존재
거리측정방식
1. L1 : Manhattan distance
어떤 좌표계인지에 영향을 많이 받음
좌표축을 따르는 경향 존재
-> 특징 벡터 각각 개별적인 의미를 지닌다면 L1이 유용
2.L2 : Euclidean distance
어떤 좌표계인지 영향받지않음
좌표축을 고려하지않고 자연스럽게 나눠지는 경계로 설정
-> 특징 벡터가 일반적이고 의미가 없는경우면 L2가 유용
KNN(K-Nearest Neighbors)
: NN의 일반화된 버전. 가까운 이웃을 k개만큼 찾고 이웃끼리 투표하는 방법. 가장 많은 득표수를 획득한 레이블로 예측하는 방법
점 : 2차원 평면상의 학습데이터 / 점의 색 : 클래스 / 영역의 색 : 가까운 학습데이터의 색깔로 칠함
→ 가장 가까운 이웃만을 보기에 벗어나는 것들이 존재(잡음, 노이즈) → K 값이 커질수록 경계가 부드러워짐. (보통 K값을 1보다 큰 값으로 설정함)
KNN이 이미지분류에서 사용되지 않는 이유
1. 테스트 시간이 오래걸림
2. 거리측정방식이 이미지간의 거리를 측정하는데에는 좋은 방법이 아님
이미지의 차이를 인식하는 방법에서 적절치 않음 <- 다른 사진임에도 L2거리측정방식으로는 모두 같다고 나옴
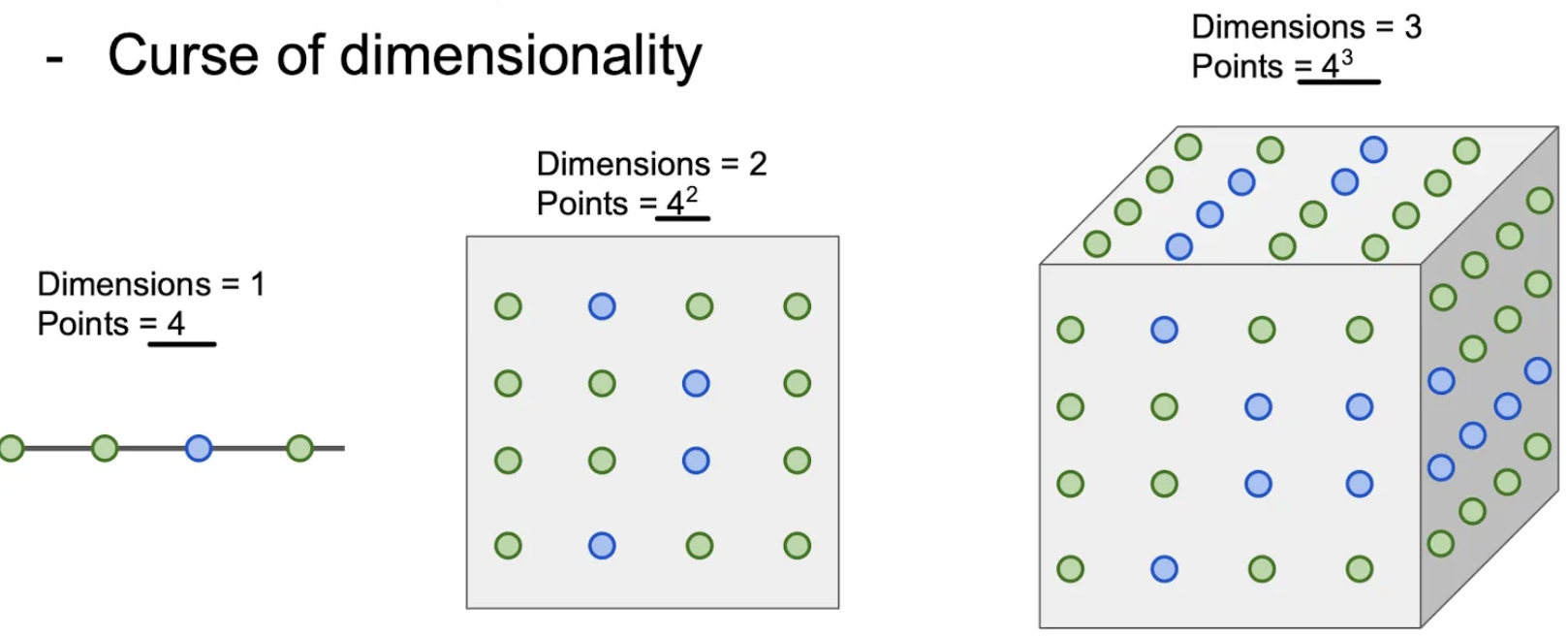
3. 차원의 저주
공간을 다룰려면 많은 훈련예제가 필요한데 차원이 증가함에따라 필요한 양은 기하급수적으로 증가함
차원이 늘어남에따라 필요한 양이 늘어남! 밀도가 높은 데이터세트가 있어야함
Hyperparameters
: 학습하기 전에 미리 알고리즘에 대한 선택들 ex_ K의 값, 거리측정방식 등
설정방법
1. 학습데이터의 최고의 정확성과 성능을 제공하는 하이퍼파라미터를 선택
2. 전체데이터를 훈련과 테스트로 나눠 훈련데이터에 다양한 하이퍼파라미터를 선택해 알고리즘을 훈련하고 훈련된 분류기를 테스트 데이터에 적용해 가장 좋은 성능의 하이퍼파라미터 세트를 선택
=> 기계학습은 보이지않는 데이터를 잘 분류해야하기에 학습에서는 좋은 성능이었다해도 이것을 일반화할 순 없음. 좋은 방법이 아님
3. 데이터를 훈련세트, 검증세트, 테스트세트로 분류. 훈련세트에서 성능을 평가하고 검증세트에서 가장 좋은성능의 하이퍼파라미터 세트를 선택해 가장 성능이 좋은 분류기를 가져와 테스트세트에서 한번 실행 -> 성능수치가 알고리즘이 보이지않는 데이터에 대해 얼마나 잘 작동하는지 알려줌
4. Cross-Validation : 교차검증, 테스트데이터만 정해놓고 훈련데이터를 여러부분으로 나누어 검증데이터를 번갈아가며 지정해줌 -> 소규모데이터세트에서 좀더 사용되는 방법. 학습자체에 계산량이 많은 딥러닝에서는 많이 이용되지 않음
Linear Classification
: CNN과 RNN을 기반한 알고리즘. 선형분류
x : 입력 데이터
w : 매개변수, 가중치
출력 : 10개의 클래스를 나타내는 숫자를 출력. 숫자 높을수록 해당 클래스에 속할 확률이 높음
입력데이터의 이미지 = 32x32x3 x = 3072(=32x32x3) x 1 W = 10(클래스) x 3072 bias = 10x1 / output = 10x1
위 예시인 고양이 사진(2x2)을 입력(X)을 받으면 가중치 파라미터(W)와 곱하여 카테고리 score 값(f(x,w))을 출력함
score값이 높을수록 고양이일 확률이 높다.
CIFAR-10예제
가중치 행렬의 행벡터를 가지고 다시 이미지로 시각화
이미지를 점과 고차원의 공간으로 둠
선형분류기가 각 클래스를 구분시키는 선형결정경계를 그어줌
한계
선형분류기가 각 클래스에대해 하나의 템플릿만 학습하는 것이 문제 한 클래스내에 다양한 특징들을 평균화시킴