이미지 내 사물을 인식하는 방법
- Semantic Segmentation
- 이미지 내에서 픽셀 단위로 categorize하는 작업
- instance 간의 구분은 없음

- Classification
- 이미지 내 사물이 “무엇인지”만을 판단
- Classification + Localization
- 이미지 내 사물이 무엇인지 판단 + 어느 위치에 있는지 바운딩
- Object Detection
- 다수의 사물이 존재하는 상황에서 분류와 위치 찾기를 진행
- Instance Segmentation
- 각각의 사물을 픽셀 단위로 구분하는 것
객체 검출 방식
2-Stage Detector
- 물체의 위치를 찾는 문제와 분류하는 문제를 순차적으로 해결하는 방법
- Region proposals : 사물이 존재할 법한 위치를 찾아 나열
- Feature Extractor : 각각의 위치를 토대로 Feature 추출
- Feature를 토대로 분류 또는 정확한 위치를 regression(bbox 예측)
- 대표적으로 R-CNN, Fast R-CNN, Faster R-CNN
1-Stage Detector
- 물체의 위치를 찾는 문제와 분류하는 문제를 한 번에 해결하는 방법
- 2-Stage 방식보다 더 빠르게 동작하지만 정확도가 떨어짐
- 대표적으로 YOLO
Region Proposal
Sliding Window
- 이미지에서 다양한 형태의 윈도우를 슬라이딩하여 존재하는지 확인
- 너무 많은 영역에서 확인해야한다는 단점 존재
- Faster R-CNN에서 사용됨 (GPU 이용)
Selective Search
- 인접한 영역(region)끼리 유사성을 측정해 큰 영역대로 차례대로 통합해 나감
- CPU 기반으로 수행되도록 라이브러리가 작성됨
- R-CNN, Fast R-CNN에서 사용됨
R-CNN
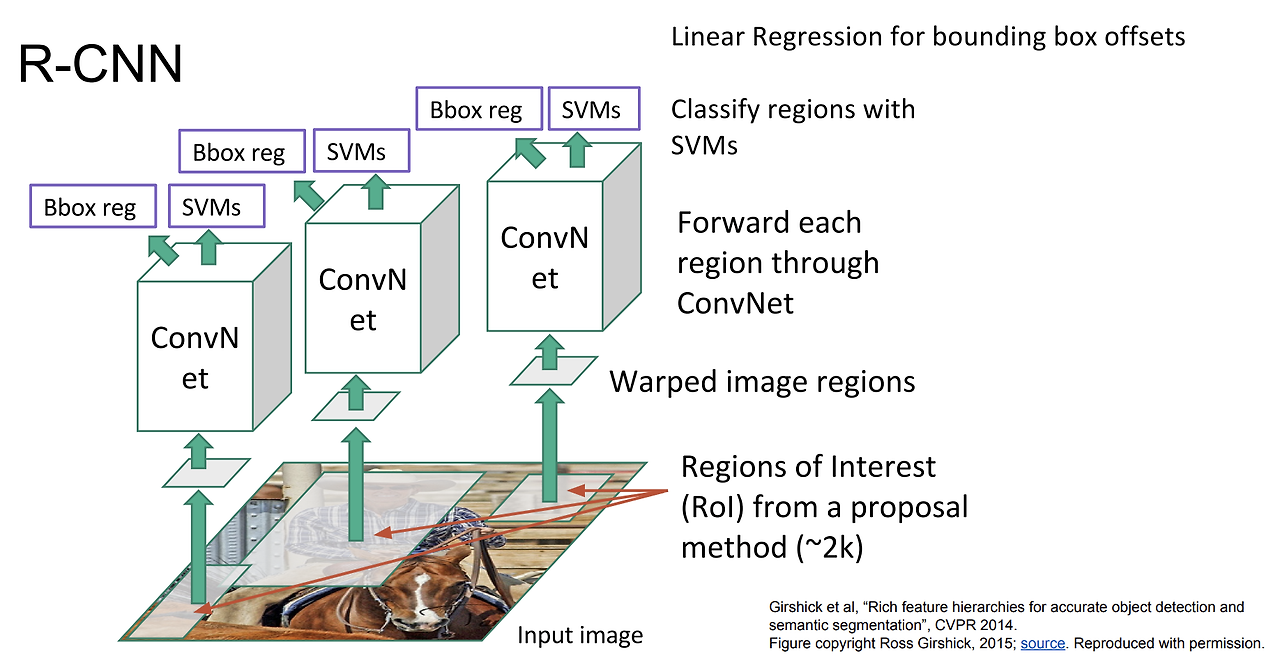
- CPU상에서 Selective Search를 진행 - 물체가 존재할 듯한 위치(RoI) 약 2000개를 찾음
- 각 RoI에 대해 warping을 수행하여 동일한 크기의 입력 이미지로 변경
- 2000개의 물체를 개별적으로 CNN에 forward하여 Feature vector 추출
- Feature Vector 바탕으로 SVM(분류)과 Regressor(정확한 물체 위치)를 진행
- 문제점
- 계산 비용이 높음
- 학습 과정과 테스트 과정이 오래 걸림
- CNN과 SVM, Regressor 모듈의 분리로, end-to-end 로 동작할 수 없음 (정확도 낮음)
Fast R-CNN

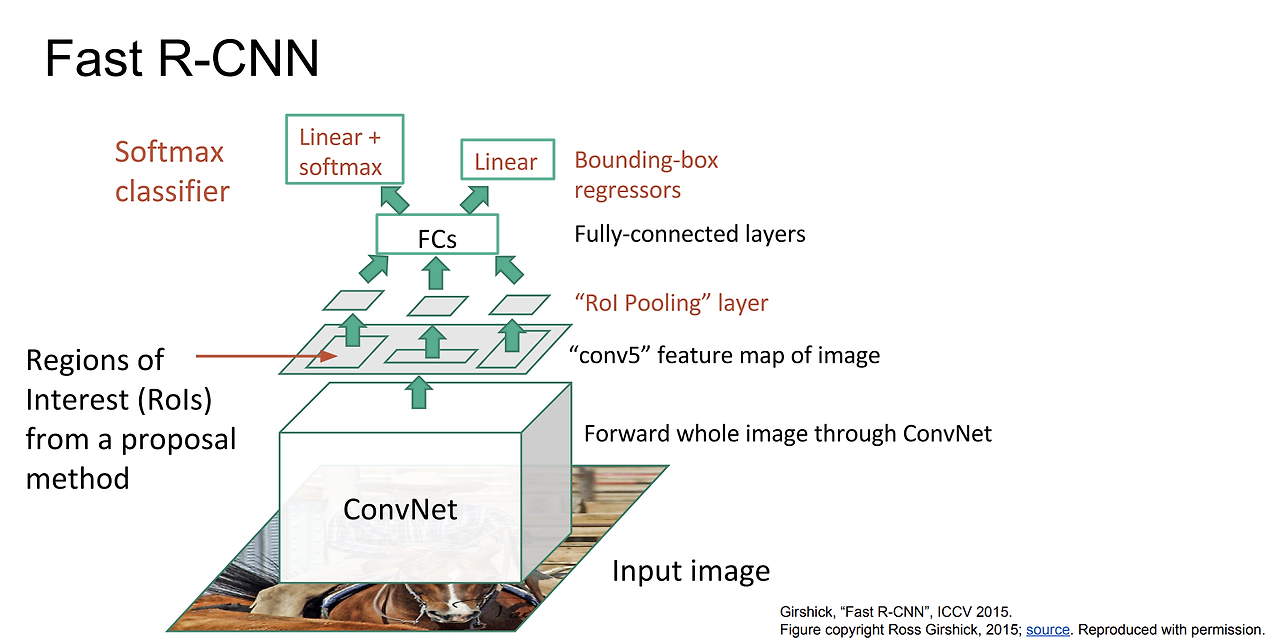
- 기존의 R-CNN 기법의 성능을 개선한 모델 (속도적인 측면에서 많은 향상)
- Selective Search를 진해앟여 약 2000개를 찾음 (R-CNN과 동일)
- Feature map 을 뽑기 위해 CNN을 한 번만 거침
- RoI Pooling을 통해 각각의 region들에 대해 Feature에 대한 정보를 추출
- RoI Pooling : 기존의 RoI를 H x W Grid로 나누고, 각 Cell에서 Max Pooling을 수행하여 H x W 크기의 고정된 Feature Map을 생성하는 작업
- CNN의 구조는 Feature map은 input 이미지에 대해 위치 정보를 어느정도 보존하고 있음
- Softmax Layer를 거쳐 각각의 class에 대한 확률을 구함
- 문제점
- R-CNN보다는 속도가 빨라졌지만 여전히 CPU를 사용하는 Region Proposal에서 많은 시간 소요
Faster R-CNN

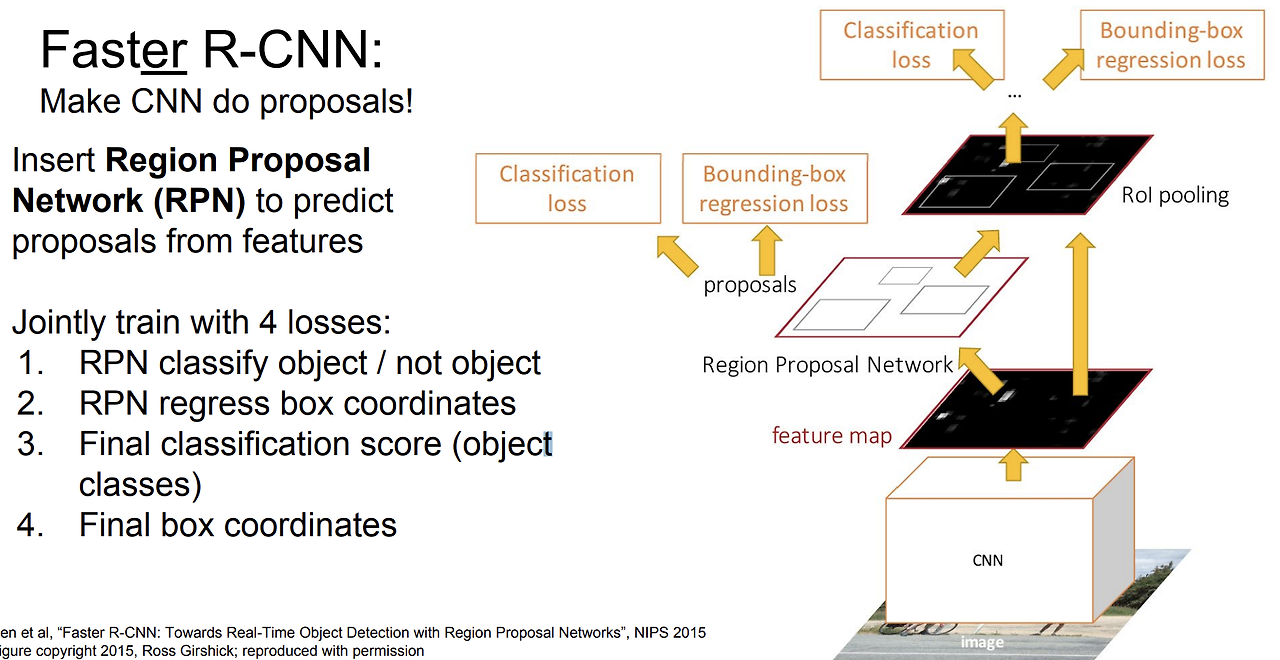
- 앞선 두 모델과 달리 Region Proposal에서 GPU를 사용 (RPN)
- RPN : Feature map을 보고 어느 곳에 물체가 있을 법 한지 예측할 수 있도록 함
- Selective Search의 시간적인 단점을 해결하는 대안
- k 개의 앵커 박스를 이용
- 슬라이딩 윈도우를 거쳐 각 위치에 대해 Regression과 Classification을 진행
- 학습이 이뤄진 뒤에 GPU에 상에서 한 번의 포워딩만 수행
- 이 후 Fast R- CNN과 동일한 아키텍쳐로 진행
- 모든 과정을 end-to-end 방식으로 학습될 수 있음
코드 실습
import torch
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
import torchvision.transforms as T
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.patches as patches
# 1. 사전 학습된 Faster R-CNN 모델 불러오기
# torchvision 라이브러리에서 COCO 데이터셋으로 사전 학습된 Faster R-CNN 모델을 불러오기
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.eval() # 평가 모드로 설정하여 추론만 진행
# 2. 이미지 전처리 함수 정의
# Faster R-CNN은 이미지의 크기나 색상값을 일정한 형식으로 전처리해야 하므로, 이를 위한 변환을 정의
def transform_image(image_path):
image = Image.open(image_path).convert("RGB")
transform = T.Compose([
T.ToTensor(), # 이미지를 Tensor로 변환
])
return transform(image)
# 3. 객체 검출 함수 정의
# 입력 이미지에서 객체를 검출하고, 결과를 출력하는 함수
def detect_objects(image_path):
# 이미지 전처리
image = transform_image(image_path)
# 모델에 입력할 수 있도록 배치 차원을 추가합니다.
image = image.unsqueeze(0)
# 객체 검출 실행
with torch.no_grad(): # 추론 과정에서의 메모리 사용을 최적화하기 위해 gradient를 계산하지 않음
predictions = model(image)
# 예측 결과에서 필요한 정보 추출
boxes = predictions[0]['boxes'] # 객체의 경계 상자
labels = predictions[0]['labels'] # 객체 클래스 레이블
scores = predictions[0]['scores'] # 신뢰도 점수
return boxes, labels, scores
# 4. 결과 시각화 함수 정의
# 객체 검출 결과를 시각적으로 보여주기 위해, 원본 이미지에 경계 상자를 그려 출력하는 함수
def plot_detections(image_path, boxes, labels, scores, threshold=0.8):
image = Image.open(image_path)
plt.figure(figsize=(12, 8))
plt.imshow(image)
ax = plt.gca()
# 객체마다 경계 상자를 그림
for box, label, score in zip(boxes, labels, scores):
if score >= threshold: # 신뢰도 점수가 임계값 이상일 때만 표시
xmin, ymin, xmax, ymax = box
rect = patches.Rectangle(
(xmin, ymin), xmax - xmin, ymax - ymin,
linewidth=2, edgecolor='r', facecolor='none'
)
ax.add_patch(rect)
ax.text(xmin, ymin, f'{label.item()} ({score:.2f})',
color='white', fontsize=12, bbox=dict(facecolor='red', alpha=0.5))
plt.axis('off')
plt.show()
# 5. 테스트할 이미지 경로 설정 (Colab에서 이미지를 업로드하고 경로를 설정)
image_path = "이미지 경로" # 검출하고자 하는 이미지 경로
# 6. 객체 검출 실행 및 시각화
boxes, labels, scores = detect_objects(image_path)
plot_detections(image_path, boxes, labels, scores)이미지 출처 : https://youtu.be/nDPWywWRIRo https://youtu.be/jqNCdjOB15s
'Group Study (2024-2025 Q1) > Machine Learning 심화' 카테고리의 다른 글
| [ML심화] 7주차 스터디 (0) | 2024.11.17 |
|---|---|
| [ML 심화] 6주차 스터디 - YOLO (0) | 2024.11.12 |
| [ML심화 ] 4주차 스터디 (0) | 2024.10.29 |
| [ML심화] 3주차 스터디 (1) | 2024.10.15 |
| [ML심화] 2주차 스터디 - Loss Function, Optimization, Back Propagation, Neural Network (9) | 2024.10.08 |