논문리뷰 _ YOLOv3 : an incremental improvement
- 1, 2 stage detector / YOLO
- YOLO의 motivation
YOLO는 정확한 성능보다는 real-time application을 위한 빠른 속도의 알고리즘에 초점을 둠
- YOLO의 motivation
- 1 stage detector
region proposal과 object분류 과정이 별도의 네트워크로 분리됨 (2개의 stage로 분리됨)
detection의 성능은 상대적으로 낮지만 inference 속도가 상대적으로 높음 - 2 stage detector
region proposal과 object분류 과정이 별도의 네트워크로 분리되지않음 (1개의 stage로)
detection의 성능은 상대적으로 높지만 inference 속도가 상대적으로 낮음
주요 내용
- bounding box prediction
파란색 표시 : bounding box / 검은색 점선 표시 : anchor box파란색박스의 중점, 가로 세로 값을 구해 최종적으로 파란색박스를 구함! - YOLO v2부터는 anchor box라는 prior box를 설정해 최종 bounding box예측에 활용함
- 정규화를 해주어 bounding box가 1을 벗어나지 않도록 크기를 조정해줌

Loss
- B-box regression loss
- 예측한 B-box와 Groundtruth B-box의 오차 제곱을 계산
- 1이라고 표시된 indicate function → B-box에 대해서만 연산하도록 함
- ⇒ loss연산과 업데이트를 효율적으로 하기 위함
- B-box width, height 부분에서 제곱근은 절대적인 값이 커짐으로 오류가 커지게되는 왜곡을 막기위해 사용
- 람다라는 가중치를 둠으로써 스케일링을 진행 ← 일종의 균형을 맞춰주기위한 balance parameter
- object confidence loss
- object 확률값 x iou값 - Groundtruth과의 오차제곱을 계산람다 가중치를 붙여줌 보통 0.5임 → 클래스 불균형 문제를 해소시키기위함(물체보다 배경에 집중되지않게하기위해서)
- 없어야하는 배경에대해서도 점수를 구해 계산에 포함시킴
- classification loss클래스별 확률값에 대한 오차 제곱으로 계산
과정
- bounding box prediction (with anchor box)
anchor box의 크기는 데이터셋 이미지의 object 크기를 clustering하여 계산
v3에서는 총 9개로 clustering함
1개의 cell에서 여러개의 anchor box를 통해 개별 cell에서 여러개의 object detection을 진행 - binary prediction per every class
logistic classifier를 사용함 (하나로만 가는 softmax classifier를 사용하지 않음)
binary crss entropy loss를 사용함 - feature extractor
Darknet-53
- : YOLO v2의 backbone(Darknet-19)에 residual network 요소를 더함총 53개의 convolution layer를 사용함YOLO v2의 backbone(Darknet-19)보다 높은 성능을 지님
- SOTA(Resnet 101, Resnet 152) 구조 대비 대등한 성능 및 효율적인 연산
- bottle neck구조로, short-cut을 도입함
YOLO v3
coco datatset성능을 높일 수 있도록 디자인되어짐
- input 이미지 → feature map(down sampling) → 19x19 detection → 2배로 사이즈업 → detection → 2배로 사이즈업 → detection
- ExperimentSSD계열인 DSSD와 유사한 AP성능을 보이면서도, 속도는 3배 빠름RetinaNet을 제외한 다른 모델에 대해서 AP성능이 대부분 높거나, 상단을 이루는 것을 확인
output feature map
- Objectness score : object일 확률 x IOU 값⇒ Box Co-ordinates x objectness socre x class scores x bounding box 수
- classs score : 각 class 별 score 값
- Box Co-ordinates : bounding box의 x, y, w, h 값
- pascal voc, coco dataset
Experiment
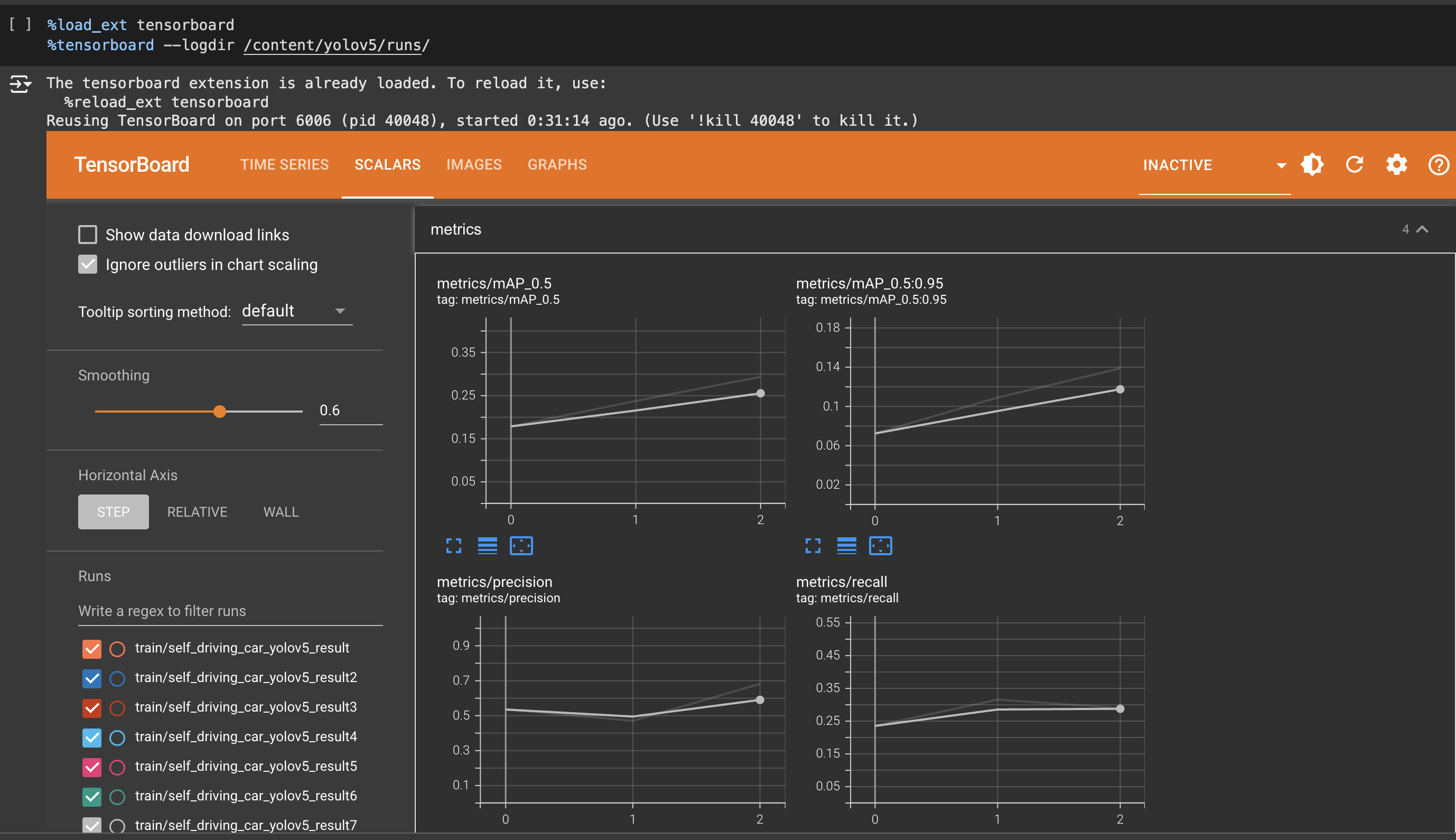
- IOU 0.5 metric에 대해, 정확도는 유사하면서 추론 속도가 매우 높은 것을 확인
- APs(: small object에대한 정확도)에 대한 성능이 v2에 비해 약 3배 높아짐
- 의미
multi scale(3개)의 feature map output에서 각각 서로 다른 크기의 anchor box로 detection 진행 → 보다 다양한 크기의 object에 대한 detection 성능 향상multi label prediction : softmax가 아닌 logistic classifier로 binary prediction 문제로 치환
1개의 이미지에 대해서 총 9개의 anchor box를 지니게 됨
backbone 성능 향상 : Darknet - 53
논문리뷰 _ YOLOv4 : Optimal Speed and Accuracy of Object Detection
- Backgroud
이제는 더이상 CV연구를 하지 않겠다고 하심
joseph redmon, YOLO v1~ YOLO v3, YOLO 9000
Related works
- object detectionbackbone : pretrained된 모델들을 주로 사용함(darknet53)
- head : one stage detection / two stage detection 나누는 부분
- neck : backbone과 head부분을 연결해줌. f eature에대한 아키텍처
- BoF(bag of freebies) : 효과적이고, 효율적인 학습을 위한 기법들
Data augmentation, Normalization(batch normalization), Object Function, Regularization method - BoS(bag of specials) : 정확도 향상을 위한 추가 모듈 기법 및 후처리 방법
Enlarging Receptive Field, feature integration, Attention mechanism
- YOLO v4 모델
backbone으로 Darknet 53 사용
큰 해상도 이미지를 다루기위해 더 많은 layer로 큰 receptive field
CSP(cross stage partial) : CSPNet에서 제안된 방법으로, 보다 더 효율적인 연산을 할 수 있는 아키텍처 구조
다양한 크기의 물체를 탐지하기위해 더 큰 capacity 모델
작은 물체를 탐지하기위해 더 큰 해상도 이미지를 사용 - BoF, BoS
여러 실험을 진행하였고, 결국에는 초록색으로 표시된 것들을 사용하게 됨
- Mosaic : 여러가지 이미지를 붙여서 한 장의 이미지로 만드는 방법4장의 이미지를 한장으로 합친것이기에.. batchsize를 4로 한 효과가 존재
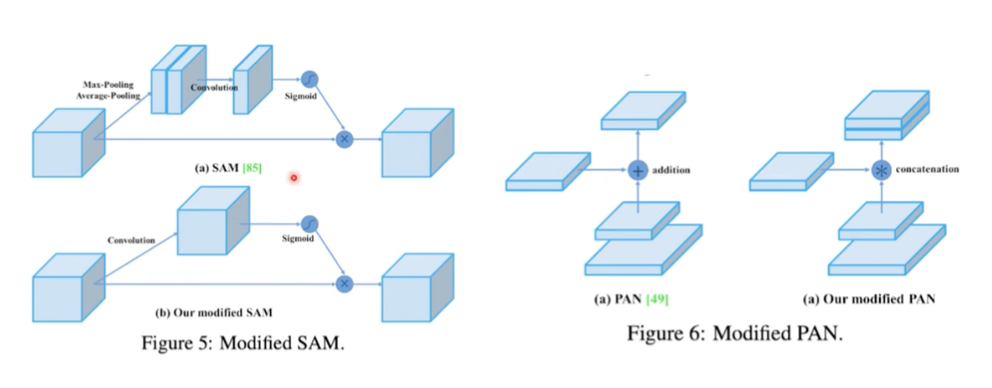
- Modified SAM, PAN
- Modified SAM : 이미지 → max pooling, average pooling → convultion으로 하나의 이미지로 → sigmoid를 씌워 0~1까지 값을 갖게됨 → 원래 이미지와 곱해줌 (attention 적용)
- Modified PAN : 기존의 feature map을 더한 방식 → feature map을 concat한 방식
- Cross mini-batch normalizationCmBN : 기존의 batch를 더 작게 batch로 나누어서 적용한 것
- Backbone : CSPDarknet 53 모델을 사용
- Neck : SPP, PAN 방법들을 사용
- Head : YOLOv3와 동일한 것을 사용Methodology

- backbone에서와 detector에서 각각 사용된 것을 볼 수 있음

Experiments
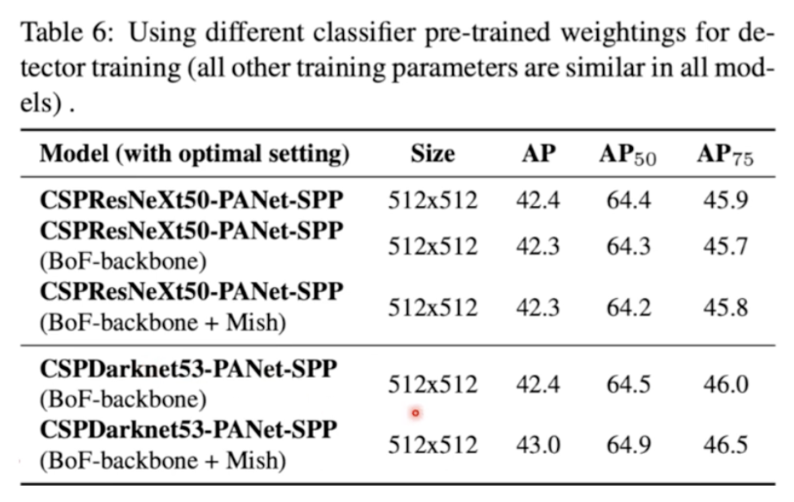
- classifier training
2가지 모델로 계속해서 실험함
CSPDarknet-53, CSPResNeXt-50
⇒ CutMix, Mosaic, Label Smoothing, Mish 적용했을때 가장 좋은 성능을 보임
- detector training
- Bag-of Freebies
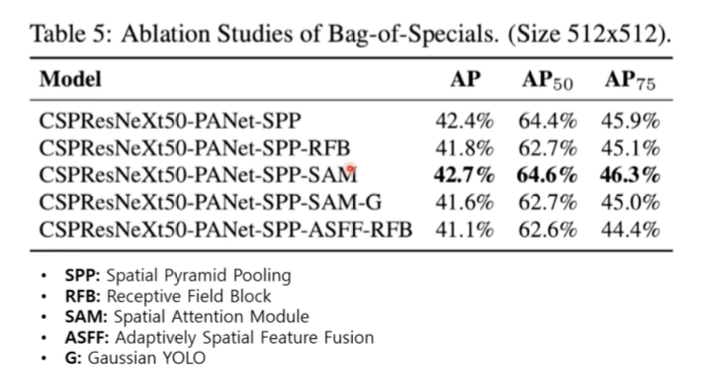
S, M, IT, GA, OA, GIoU/CIoU를 적용했을때 가장 좋은 성능을 보임 - Bag-of Specials
SPP-SAM을 적용했을때 가장 좋은 성능을 보임 - classifier vs detection
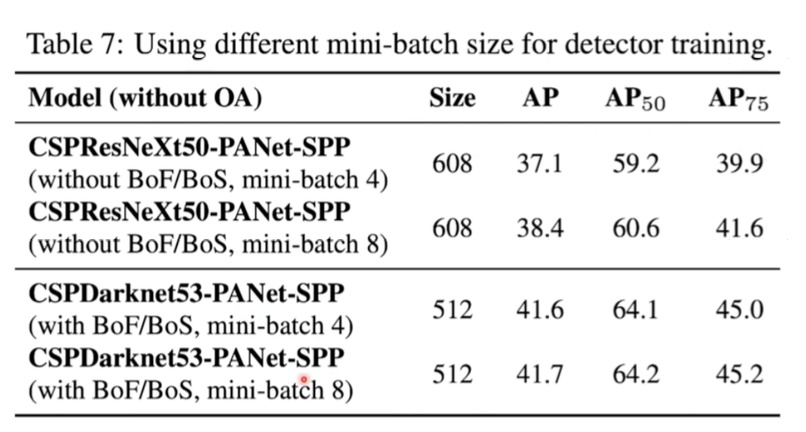
꼭 classification에서 성능이 좋다고해서 detection에서도 좋은 것은 아님 - mini-batch
ResNeX와 다르게 Darknet53에서는 mini-batch를 작게해도 성능은 거의 변동없이 보장됨
- Bag-of Freebies
- Conclusion
YOLOv3를 개선한 더 빠르고, 정확한 모델을 제안한 것
Single GPU환경에서 사용가능한 모델
YOLOv3을 개선한 더 빠르고 정확한 모델을 제안한 것
YOLOv3을 개선한 더 빠르고 정확한 모델을 제안한 것
YOLOv3을 개선한 더 빠르고 정확한 모델을 제안한 것

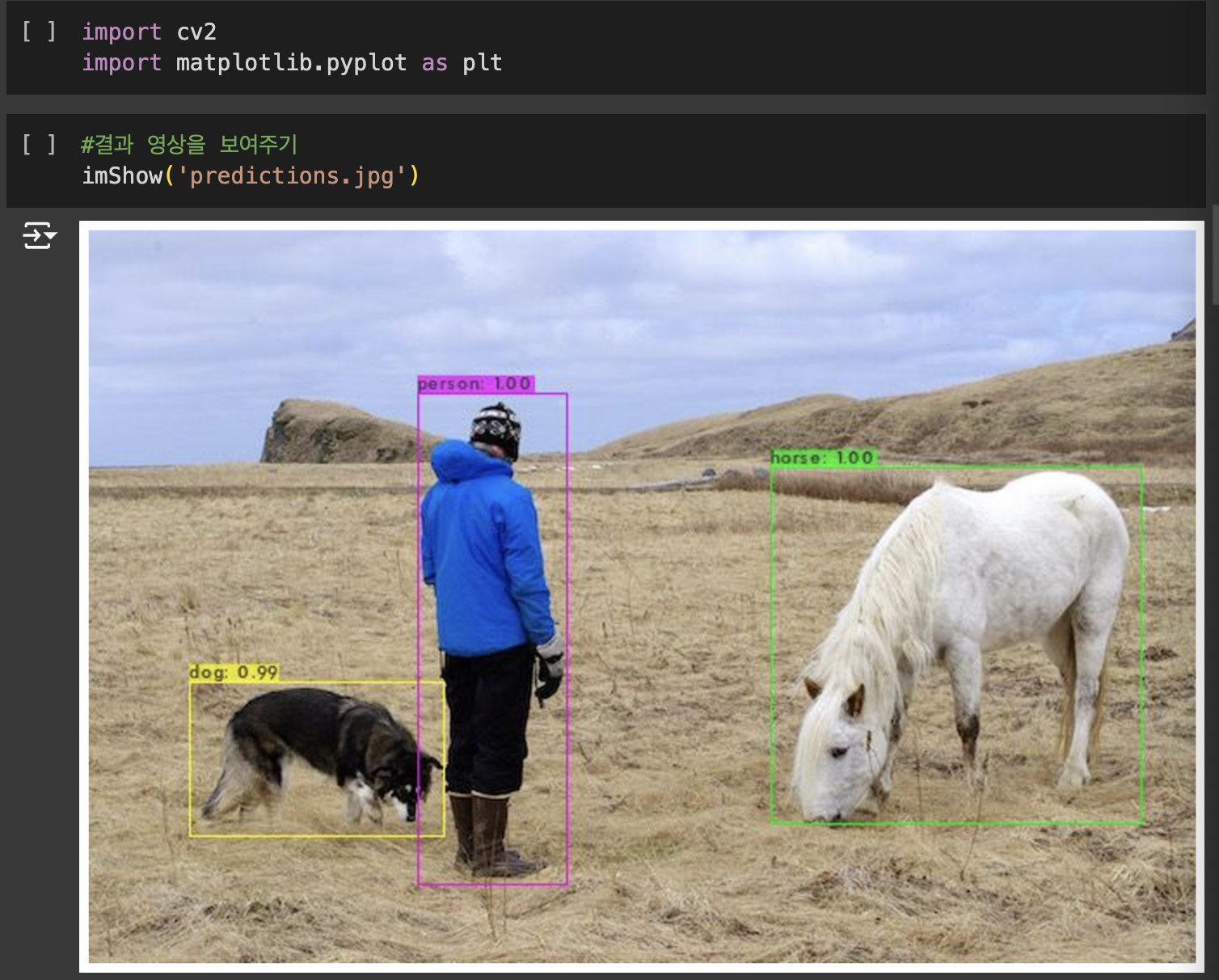
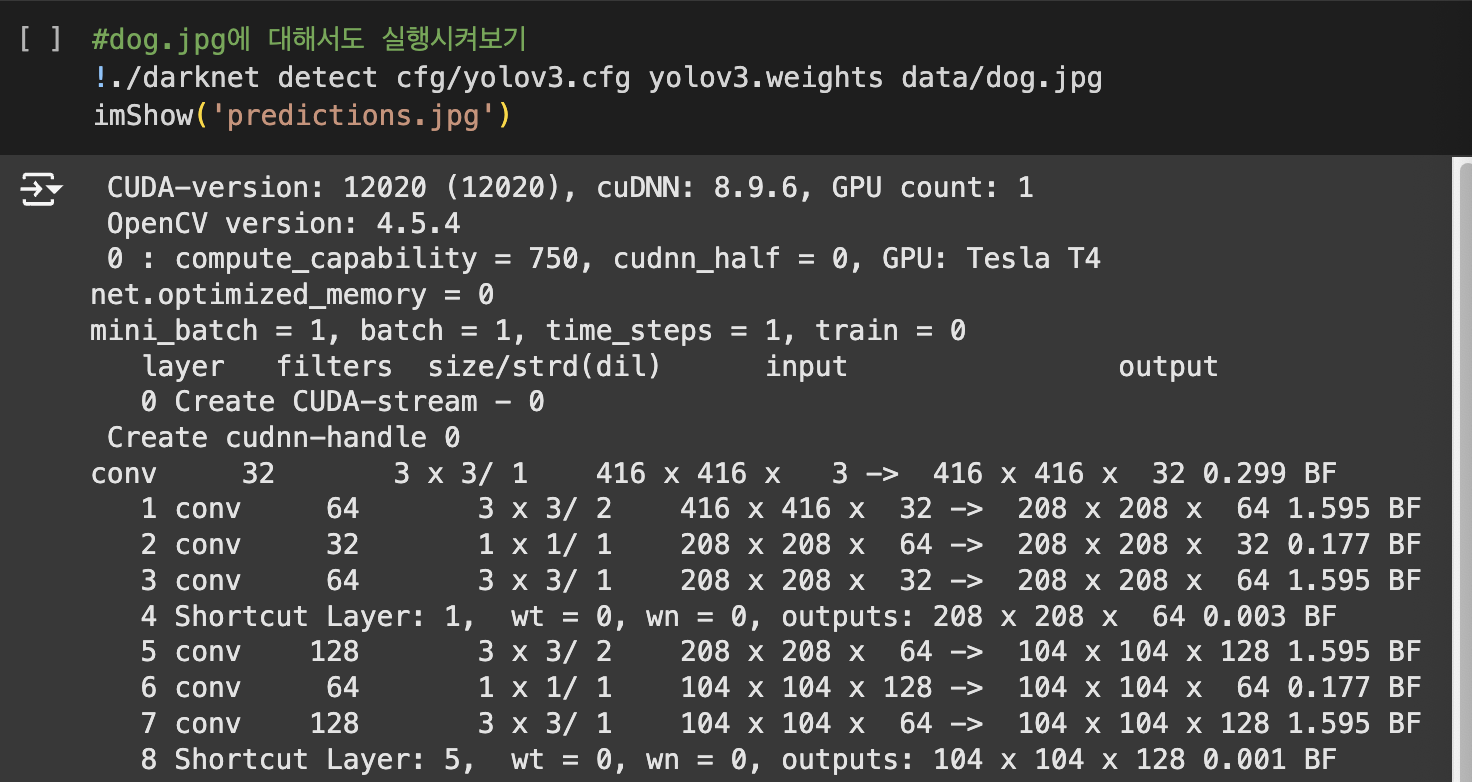
실습
YOLO v3
YOLO v5
'Group Study (2024-2025 Q1) > Machine Learning 심화' 카테고리의 다른 글
| [ML 심화] 8주차 스터디 - U-Net , CS231n - Assignment1 inline question 답 (0) | 2024.11.26 |
|---|---|
| [ML 심화] 6주차 스터디 - YOLO (0) | 2024.11.12 |
| [ML 심화] 5주차 스터디 - Object Detection: 2-stage-detector (0) | 2024.11.05 |
| [ML심화 ] 4주차 스터디 (0) | 2024.10.29 |
| [ML심화] 3주차 스터디 (1) | 2024.10.15 |