
데이터베이스를 사용하는 이유
데이터베이스가 존재하기 이전에는 파일 시스템을 이용하여 데이터를 관리하였다. (현재도 부분적으로 사용되고 있다.) 데이터를 각각의 파일 단위로 저장하며 이러한 일들을 처리하기 위한 독립적인 애플리케이션과 상호 연동이 되어야 한다. 데이터를 파일 단위로 저장할때 데이터 종속성 문제와 중복성, 데이터 무결성문제가 존재한다.
데이터베이스의 특징
1. 데이터의 독립성
- 물리적 독립성 : 데이터베이스 사이즈를 늘리거나 성능 향상을 위해 데이터 파일을 늘리거나 새롭게 추가하더라도 관련된 응용 프로그램을 수정할 필요가 없다.
- 논리적 독립성 : 데이터베이스는 논리적인 구조로 다양한 응용 프로그램의 논리적 요구를 만족시켜줄 수 있다.
2. 데이터의 무결성
: 여러 경로를 통해 잘못된 데이터가 발생하는 경우의 수를 방지하는 기능으로 데이터의 유효성 검사를 통해 데이터의 무결성을 구현하게 된다.
3. 데이터의 보안성
: 인가된 사용자들만 데이터베이스나 데이터베이스 내의 자원에 접근할 수 있도록 계정 관리 또는 접근 권한을 설정함으로써 모든 데이터에 보안을 구현할 수 있다.
4. 데이터의 일관성
: 연관된 정보를 논리적인 구조로 관리함으로써 어떤 하나의 데이터만 변경했을 경우 발생할 수 있는 데이터의 불일치성을 배제할 수 있다. 또한 작업 중 일부 데이터만 변경되어 나머지 데이터와 일치하지 않는 경우의 수를 배제할 수 있다.
5. 데이터 중복 최소화
: 데이터베이스는 데이터를 통합해서 관리함으로써 파일 시스템의 단점 중 하나인 자료의 중복과 데이터의 중복성 문제를 해결할 수 있다.
정규화
정규화란?
관계형 데이터베이스에서 중복을 최소화하기 위해 데이터를 구조화하는 작업이다. 구체적으로는 불만족스러운 나쁜 릴레이션의 애트리뷰트들을 나누어서 좋은 작은 릴레이션으로 분해하는 작업을 말한다. 정규화 과정을 거치게 되면 정규형을 만족하게 된다. 정규형이란 특정 조건을 만족하는 릴레이션의 스키마의 형태를 말하며 제1 정규형, 제2 정규형, 제3 정규형, BCNF 등이 존재한다.
정규형의 종류
제1 정규형
애트리뷰트의 도메인이 오직 원자 값만을 포함하고, 튜플의 모든 애트리뷰트가 도메인에 속하는 하나의 값을 가져야 한다. 즉, 복합 애트리뷰트, 다중 값 애트리뷰트, 중첩 릴레이션 등 비 원자적인 애트리뷰트들을 허용하지 않는 릴레이션 형태를 말한다.
제2 정규형
모든 비주요 애트리뷰트들이 주요 애트리뷰트에 대해서 완전 함수적 종속이면 제2 정규형을 만족한다고 볼 수 있다. 완전 함수적 종속이란 X -> Y라고 가정했을 때, X의 어떠한 애트리뷰트라도 제거하면 더 이상 함수적 종속성이 성립하지 않는 경우를 말한다. 즉, 키가 아닌 열들이 각각 후보 키에 대해 결정되는 릴레이션 형태를 말한다.
제3 정규형
어떠한 비주요 애트리뷰트도 기본키에 대해서 이행적으로 종속되지 않으면 제3 정규형을 만족한다고 볼 수 있다. 이행 함수적 종속이란 X ->Y, Y -> Z의 경우에 의해서 추론될 수 있는 X -> Z의 종속관계를 말한다. 즉, 비주요 애트리뷰트가 비주요 애트리뷰트에 의해 종속되는 경우가 없는 릴레이션 형태를 말한다.
BCNF(Boyce-Codd) 정규형
여러 후보 키가 존재하는 릴레이션에 해당하는 정규화 내용이다. 복잡한 식별자 관계에 의해 발생하는 문제를 해결하기 위해 제3 정규형을 보완하는데 의미가 있다. 비주요 애트리뷰트가 후보 키의 일부를 결정하고 분해하는 과정을 말한다.
정규화의 장점
1. 데이터베이스 변경 시 각종 이상 현상들이 발생하는 문제점을 해결할 수 있다.
2. 데이터베이스 구조 확장 시 재 디자인 최소화 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다. 이는 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미치게 되며 응용프로그램의 생명을 연장시킨다.
3. 사용자에게 데이터 모델을 더욱 의미 있게 제공하는 정규화된 테이블들과 정규화된 테이블들 간의 관계들은 현실 세계에서의 개념들과 그들 간의 관계들을 반영한다.
정규화의 단점
릴레이션의 분해로 인해 릴레이션 간의 연산(JOIN 연산)이 많아진다. 이로 인해 질의에 대한 응답 시간이 느려질 수 있다. 정규화를 수행한다는 것은 데이터를 결정하는 결정자에 의해 함수적 종속을 가지고 있는 일반 속성을 의존자로 하여 입력/수정/삭제 이상을 제거하는 것이다. 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다. 따라서 정규화된 테이블은 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있는 특성이 있다.
Join
조인이란?
한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한 것이다.
따라서 조인은 테이블로서 저장되거나, 그 자체로 이용할 수 있는 결과 셋을 만들어 낸다.
조인의 필요성
관계형 데이터베이스의 구조적 특징으로 정규화를 수행하면 의미 있는 데이터의 집합으로 테이블이 구성되고, 각 테이블끼리는 관계(Relationship)를 갖게 된다.
이와 같은 특징으로 관계형 데이터베이스는 저장 공간의 효율성과 확장성이 향상되게 된다.
다른 한편으로는 서로 관계있는 데이터가 여러 테이블로 나뉘어 저장되므로, 각 테이블에 저장된 데이터를 효과적으로 검색하기 위해 조인이 필요하다.
조인의 종류
내부 조인(INNER JOIN)

여러 애플리케이션에서 사용되는 가장 흔한 결합 방식이며, 기본 조인 형식으로 간주된다.
내부 조인은 조인 구문에 기반한 2개의 테이블(A, B)의 칼럼 값을 결합함으로써 새로운 결과 테이블을 생성한다.
명시적 조인 표현(explicit)과 암시적 조인 표현(implicit) 2개의 다른 조인식 구문이 있다.
명시적 조인 표현
테이블에 조인을 하라는 것을 지정하기 위해 JOIN 키워드를 사용하며, 예제와 같이 ON 키워드를 조인에 대한 구문을 지정하는 데 사용한다.
SELECT *
FROM table1 INNER JOIN table2
ON table1.colum = table2.colum;
암시적 조인 표현
SELECT 구문의 FROM 절에서 그것들을 분리하는 컴마를 사용해서 단순히 조인을 위한 여러 테이블을 나열하기만 한다.
SELECT *
FROM table1, table2
WHERE table1.colum = table2.colum;
동등 조인(EQUI JOIN)
자연 조인(NATURAL JOIN)
교차 조인(CROSS JOIN)
외부 조인(OUTER JOIN)
조인 대상 테이블에서 특정 테이블의 데이터가 모두 필요한 상황에서 외부 조인을 활용하여 효과적으로 결과 집합을 생성할 수 있다.
왼쪽 외부 조인(LEFT OUTER JOIN)
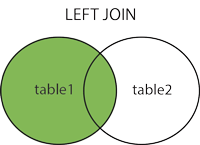
우측 테이블에 조인할 칼럼의 값이 없는 경우 사용한다.
즉, 좌측 테이블의 모든 데이터를 포함하는 결과 집합을 생성한다.
SQL
SELECT *
FROM table1 LEFT OUTER JOIN table2
ON table1.colum = table2.colum;
오른쪽 외부 조인(RIGHT OUTER JOIN)
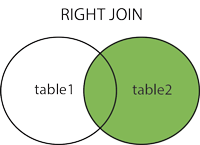
좌측 테이블에 조인할 컬럼의 값이 없는 경우 사용한다.
즉, 우측 테이블의 모든 데이터를 포함하는 결과 집합을 생성한다.
SQL
SELECT *
FROM table1 RIGHT OUTER JOIN table2
ON table1.colum = table2.colum;
완전 외부 조인(FULL OUTER JOIN)

양쪽 테이블 모두 OUTER JOIN이 필요할 때 사용한다.
SQL
SELECT *
FROM table1 FULL OUTER JOIN table2
ON table1.colum = table2.colum;
셀프 조인(SELF JOIN)
Index
인덱스(Index)란?
인덱스는 색인이다. 데이터베이스에서 조회 및 검색을 더 빠르게 할 수 있는 방법/기술, 혹은 이에 쓰이는 자료구조 자체를 의미하기도 한다. 데이터는 책의 내용이고 데이터가 저장된 레코드의 주소는 인덱스 목록에 있는 페이지 번호라고 표현할 수 있다. select문을 사용하여 원하는 조건의 데이터를 검색할 때, 저장된 데이터의 양이 엄청나게 많다면 검색을 위한 순회에 많은 자원과 시간이 소모될 것이다. 그래서 칼럼의 값과 해당 레코드가 저장된 주소를 키와 값의 쌍으로 인덱스를 만들어 두는 것이다.
DBMS 의 인덱스는 항상 정렬된 상태를 유지하기 때문에 원하는 값을 탐색하는 데는 빠르지만 새로운 값을 추가하거나 삭제, 수정하는 경우에는 쿼리문 실행 속도가 느려진다. 결론적으로 DBMS에서 인덱스는 데이터의 저장 성능을 희생하고 그 대신 데이터의 읽기 속도를 높이는 기능이다. SELECT 쿼리 문장의 WHERE 조건절에 사용되는 칼럼이라고 전부 인덱스로 생성하면 데이터 저장 성능이 떨어지고 인덱스의 크기가 비대해져서 오히려 역효과만 불러올 수 있다.
INSERT : 테이블에는 입력 순서대로 저장되지만, 인덱스 테이블에는 정렬하여 저장하기 때문에 성능 저하 발생
DELETE : 테이블에서만 삭제되고 인덱스 테이블에는 남아있어 쿼리 수행 속도 저하
UPDATE : 인덱스에는 UPDATE가 없기 때문에 DELETE, INSERT 두 작업 수행하여 부하 발생
데이터의 중복이 높은 칼럼은 인덱스로 만들어도 소용없음 (예: 성별)
다중 칼럼 인덱싱할 때 카디널리티가 높은 컬럼->낮은 컬럼 순으로 인덱싱해야 효율적
중복도가 낮은 칼럼 = 카디널리티가 높은 칼럼
중복도가 높은 칼럼 = 카디널리티가 낮은 칼럼
참고
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/Database#transaction
'GDSC Sookmyung 활동 > 10 min Seminar' 카테고리의 다른 글
| CS를 공부하는 이유 (0) | 2021.06.28 |
|---|---|
| The Go Programming Language (0) | 2021.06.21 |
| IT Automation Tool : Ansible(개념, 역할, 특징, 구성요소) (0) | 2021.05.17 |
| Recoil - 새로운 리액트 상태관리 라이브러리 (0) | 2021.05.10 |
| AWS 클라우드 서비스와 AWS의 네트워킹 (0) | 2021.05.03 |