- 5주차 목표 : 자연어 처리(문서 유사도)를 이용한 추천 시스템 실습
- 참고 강의 : [구름 Edu] 딥러닝 이론 및 파이썬 실습
- 참고 자료 : inuplace.tistory.com/594
1. 자연어처리 - 문서 유사도
1. Bag of Words
: 문자를 숫자로 표현하는 방법 중 하나.
단어들의 순서를 전혀 고려하지 않고 출현 빈도에 집중하여 텍스트 데이터를 수치화해서 표현한다.
→ 머신러닝 모델의 입력값으로 사용할 수 있다.
(머신러닝 모델은 수학적 모델이므로, 입력값으로 수치화된 값이 들어가야 한다)
1) 문장 간의 유사도 구하는 방법
1. 문장의 단어마다 고유한 인덱스를 부여한 후, 각 단어의 출현 빈도를 기록한다.
2. 유사도를 구하고자 하는 문장들의 각 인덱스에 있는 값끼리 전부 곱하고 그 값을 더한다.
2) 단점
- 실제 사전에는 무수히 많은 단어가 있으므로, 문장 하나를 표현하는 데에 많은 0을 가진 길 벡터가 사용된다.
따라서 계산량도 높아지고, 메모리 사용량도 많아진다.
- 많이 출현한 단어일수록 유사도에 미치는 힘이 더 세진다.
- 오타, 줄임말 등의 데이터를 가지고 있기 힘들어 적용하기 어렵다.
- 단어의 순서를 고려하지 않으므로 문맥이 무시된다.
2. n-그램
: 연속적인 n개의 토큰으로 구성된 것.
ex ) fine thank you
1) 1-gram
- Word level : [fine, thank, you]
- Character level : [f, i, n, e, t, h, a, n, k, y, o, u]
2) 2-gram
- Word level : [fine thank, thank you]
- Character level : [fi, in, ne, e , t, th, ha, an, nk, k , y, yo, ou]
3) 3-gram
- Word level : [fine thank you]
- Character level : [fin, ine, ne , e t, th, tha, han, ank, nk , k y, yo, you]
4) n-gram 사용하는 이유는?
- bag of word를 사용할 때 단어 순서를 고려하지 않아 문맥이 무시되는 단점을 극복할 수 있다.
- 많은 자연어 처리 애플리케이션을 사용 가능하다. (다음 단어 예측/단어 스펠링 체크)
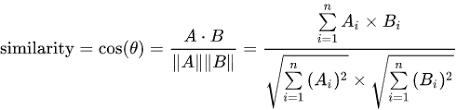
3. cosine 유사도
2. 추천 시스템
▷ Content-based filtering
: 아이템의 특성(컨텐츠 자체의 내용)을 기반으로 비슷한 아이템을 추천하는 방식
▷ Collaborative filtering
- user-based collaborative filtering
: 사용자 간의 유사도가 기준, 가장 비슷한 사용자의 아이템 중에서 추천하는 방식
- user-based collaborative filtering
: 아이템 간의 유사도가 기준, 사용자의 아이템과 가장 유사도가 높은 아이템 추천하는 방식
✔ 실습
영화 줄거리를 기준으로 Content-based filtering - 캐글 데이터 TMDB 5000 Movie Dataset 이용
# CSV 파일 불러와 DataFrame으로 저장
import pandas as pd
movies = pd.read_csv("tmdb_5000_movies.csv")
movies = movies[["original_title", "overview"]]
movies["overview"] = movies["overview"].astype("str")
전처리
# 줄거리가 NaN인 영화 drop
movies.dropna()
# "overview" column 모두 소문자로, 문자+숫자만 남기고 나머지는 띄어쓰기로 대체
import re
movies["overview"] = movies["overview"].apply(lambda x : re.sub("\W", " ", x.lower()))
TF-IDF 계산
1) TF 란?
: Term Frequency. 특정 문서에서 특정 단어의 등장 빈도.
문서가 주어졌을 때, 어떠한 단어가 여러 번 등장했다면, 등장한 만큼 단어와 문서의 연관성이 높을 것이라고 가정.
그러나, 불용어와 같이 연관성이 없어도 자주 등장하는 단어들이 있다.
→ TF만으로는 문서와 단어의 연관성 나타낼 수 없음.
2) DF 란?
: Document Frequency. 특정 단어가 등장한 문서의 수
3) IDF 란?
: log(전체 문서의 수/특정 단어가 등장한 문서의 수)
불용어처럼 연관성이 높지 않아도 자주 등장하는 단어들에게 패널티를 주기 위해 사용한다.
# TF-IDF 기반으로 단어 벡터화
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vec = TfidfVectorizer(ngram_range=(1, 2)) # Vectorizer생성 # ngram_range=(1, 2)는 단어를 1개 혹은 2개 연속으로 보겠다는 뜻
tfidf_matrix = tfidf_vec.fit_transform(movies["overview"]) # Vectorizer가 단어들을 학습
# 영화 간 cosine 유사도 구하기
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
plot_similarity = cosine_similarity(tfidf_matrix, tfidf_matrix) # 줄거리 간 cosine 유사도 구하기
print("### COSINE Similarity ###")
print(plot_similarity)
similar_index = np.argsort(-plot_similarity) # 유사도 높은 순서대로 index 정렬
print("### 유사도 기준 index 정렬 ###")
print(similar_index)
# 사용자 입력 및 결과 출력
input_movie = "Avatar" # data에 있는 영화의 제목 입력
movie_index = movies[movies["original_title"]==input_movie].index.values # input_movie에 해당하는 index 값 가져오기
similar_movies = similar_index[movie_index, :10] # 유사도 상위 10개 index 가져오기
# 인덱스로 사용하기 위해서는 1차원으로 변형
similar_movies_index = similar_movies.reshape(-1) # similar_movies 1차원 변형
display(movies.iloc[similar_movies_index])
'Group Study (2020-2021) > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 7주차 스터디 - 이미지 분석 활용 맛보기 (0) | 2020.11.24 |
|---|---|
| [Machine Learning] 6주차 스터디 - 이미지 처리 기본 (0) | 2020.11.20 |
| [Machine Learning] 4주차 스터디 - 나이브 베이즈 분류기 (0) | 2020.11.08 |
| [Machine Learning] 3주차 스터디 - 텍스트 분석 기초 (0) | 2020.10.29 |
| [Machine Learning] 2주차 스터디 - 머신러닝 기본기 다지기 (0) | 2020.10.21 |