스탠포드대학에서 발표한 CNN 강의 영상을 듣고 자료를 정리했습니다.
| Lecture 11 | Detection and Segmentation https://www.youtube.com/watch?v=nDPWywWRIRo |
Lecture 11 | Detection and Segmentation

Computer Vision Task로는 총 4가지가 있다 그 중 Segmantic Segmentation과 Classification + Locaization 과 Object Dectection를 다뤄볼 것이다.
1. Semantic Segmentation
픽셀로 모든 사물 구분한다
전체 이미지에 하나의 카테코리를 할당하는 것이 아니라 픽셀 별로 카테고리를 할당
단점 : 객체들의 개수는 파악할 수 없다. 두 마리 소도 Cow 카테고리로 묶어버림 (두 마리 소라고 구분 못함)
==> instance segmentation에서 단점 해결함
방법1: Sliding Window
1. 이미지를 작은 patch들로 쪼갠다
2. 기존 이미지 분류했던 것처럼 각각의 patch들로 classification을 진행한다.
단점
1. 매 patch 픽셀 마다 분류 연산 → 계산적으로 비용이 많이 든다
2. patch 마다 겹쳐지는 부분이 많아 같은 Conv layer을 지날 수가 있게 된다.
3. Conv layer에 넣고 출력되는 모든 픽셀에 score 적용 → spatial size를 유지해야하므로 계산 비용 크다
==> 방법: Fully Convolutional Network
전체 이미지를 Conv Layer에 넣는다.
모든 픽셀에 대해서 분류 연산을 해야한다
단점
Convolution들이 input 이미지와 같은 spatial size를 유지하는데
Channel의 숫자도 커지면 → 메모리적 비용이 매우 높다.
개선된 방법
Down Sampling & Up Sampling
모든 Conv layer들이 input 이미지의 해상도를 유지하는 대신 원본 해상도를 가진 layers의 수를 줄이고 특성 맵을 down sampling한다. 이후에 up sampling을 하며 input 이미지의 해상도가 같도록 한다.
spatial size가 작은 feature map이 많이 존재하여 깊은 Network를 형성한다.
Down Sampling 방법
Max Pooling, Strided Convolution 사용
Up Sampling 방법
Unpooling, Max Unpooling, Transpose Convolution 사용
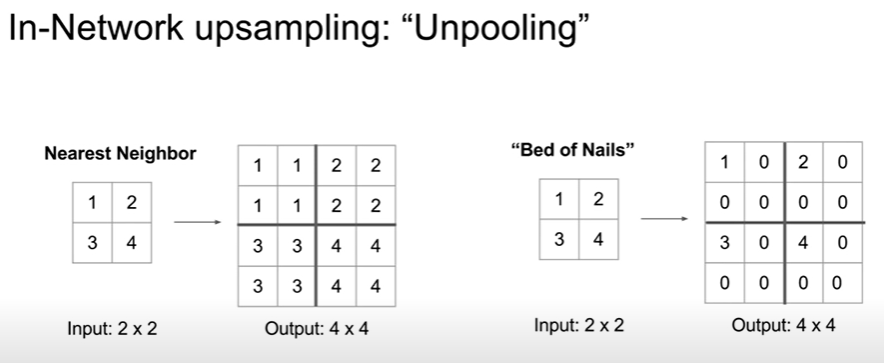
Unpooling: Neareset Neighbor Unpooling, Bed of Nails 있다.

Max Unpooling: Max pooling과 Max Unpooling 대칭적으로 사용할 수 있다
max pooling 했던 곳과 같은 곳에 max unpooling 한다
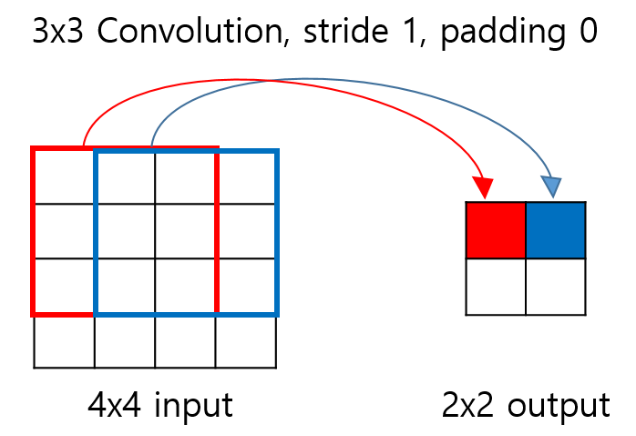
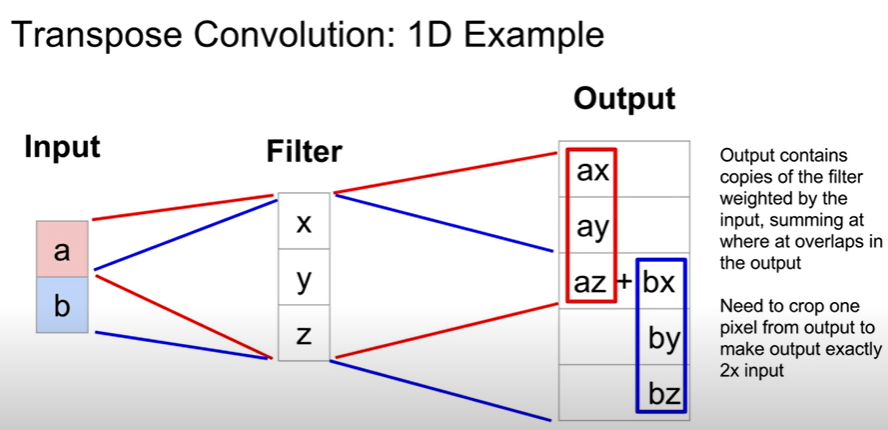
Transpose Convolution: Convolution을 거꾸로 하는 개념
학습을 통해 upsampling을 한다
2. Classification + Localization
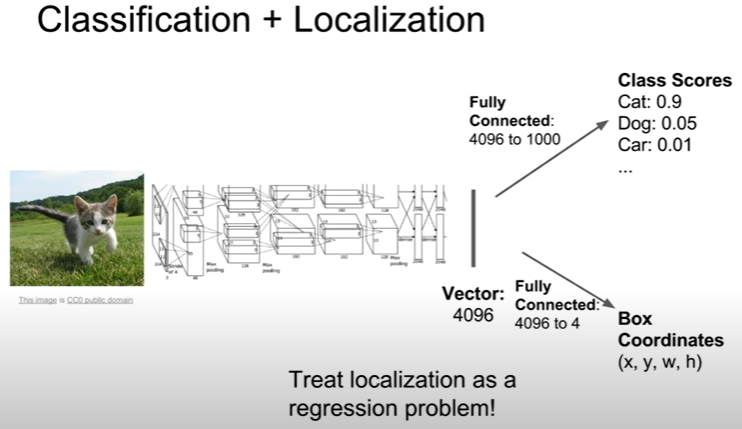
물체를 구별하는 것 뿐만 아니라 물체의 위치까지 파악한다.
물체를 찾아서 bounding box로 표시한다.
두 가지 output, loss 존재
1. class scores
2. box coordinates
두 loss를 합해서 gradient decent 진행한다
아래는 Classification + Localization의 한 예이다.
ex) human pose estimation
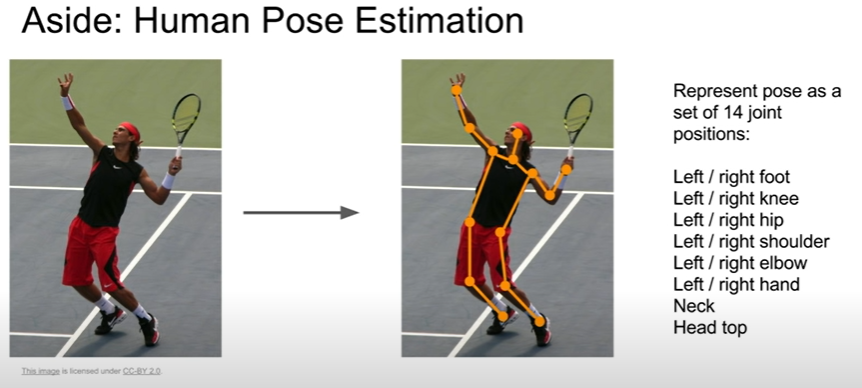
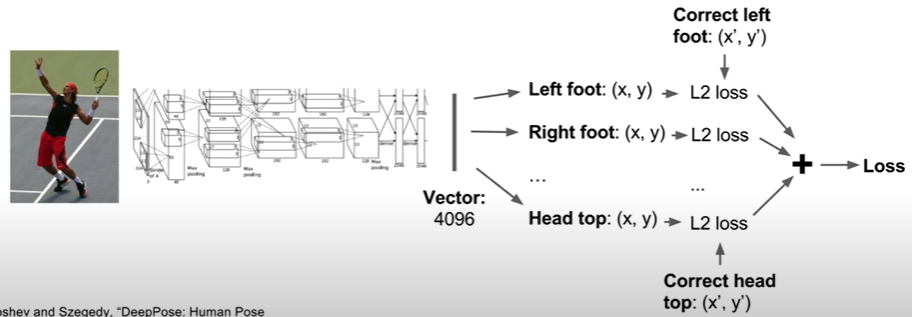
output ⇒ positions of the joints ⇒ 어떤 포즈인지 유추할 수 있음
Object Detection(객체 탐지)와의 차이점
Localization에서는 객체가 오직 하나라고 가정함
다른 이미지마다 객체의 수가 달라져 미리 예측할 수 없다.
3. Object Detection
한 장의 이미지에서 다수의 물체를 찾고, 그 물체가 어디에 있는지 알아내는 것
1-stage detector, 2-stage detector로 두 가지 방식이 존재한다
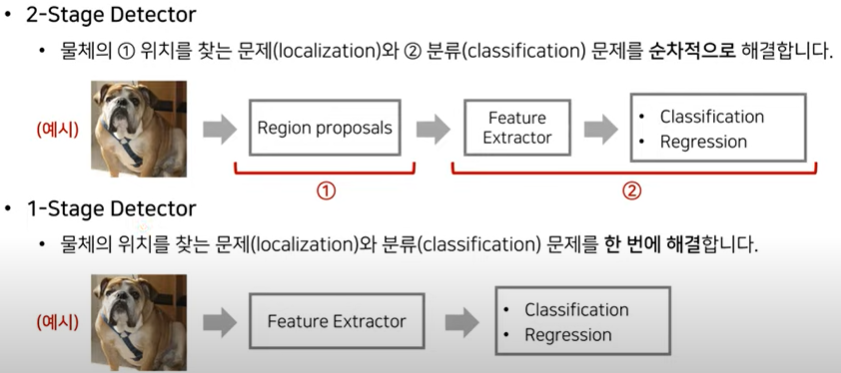
방법: Sliding Window

매 patch(crop) 별로 CNN을 진행하여 분류한다.
문제
이미지를 어떻게, 어떤 사이즈 등으로 쪼갤 것인가?(crop)
→ 수많은 방식의 crop이 존재하고, 기준도 없고, 한편으로 억지스러울 수도 있다. 그래서 이 방식을 안 쓴다
⇒ region proposal network를 이용해 객체가 있을 만한 곳을 후보로 선정한다
→ 이후에 각각 CNN을 이용하여 Classification을 진행한다

R-CNN
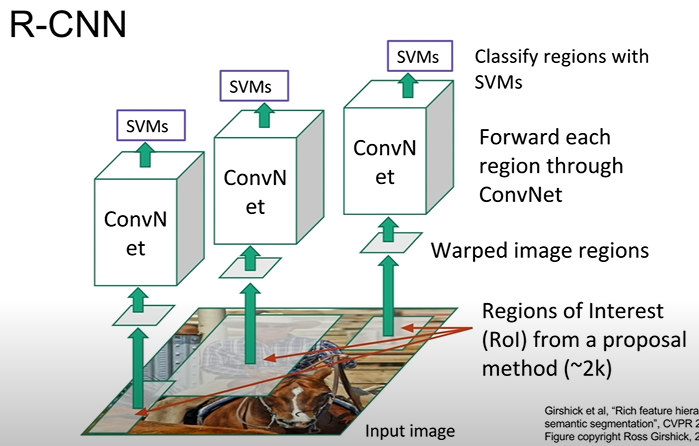
region proposal를 이용해 찾은 객체를 CNN의 input값으로 넣어 분류한다
Rol(Regions of Interest)의 size가 모두 같지 않다 → 같은 모델로 훈련시킬 수 없음 → 고정된 크기로 변환하여 CNN 진행한다 → 위 사진에서는 SVM를 이용해서 Classification을 하였다.
R-CNN에서도 bounding box로 객체의 위치 찾기를 할 수 있다, (region proposal이 항상 정확하지 않기에 사용할 필요가 있다)
문제
(모든 RoI에 대해 CNN 연산을 해야한다)
1. 계산 비용이 크다
2. 메모리를 많이 사용한다
3. 학습 과정이 느리다
4. Test Time이 느리다
속도 개선 방법 → Fast R-CNN
Fast R-CNN
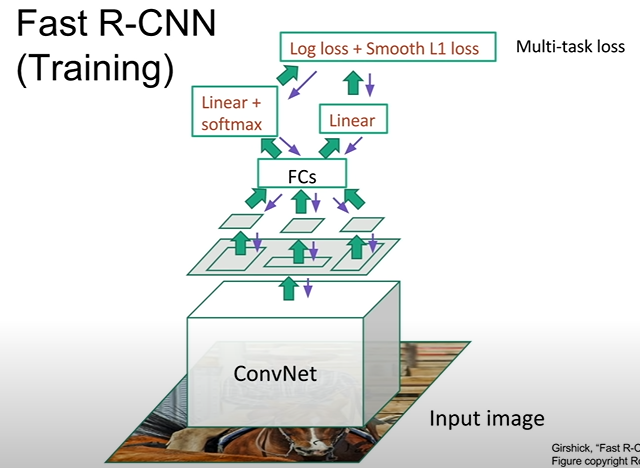
전체 이미지를 CNN을 이용해 고해상도 Feature map을 얻고, Feature map을 통해서 Regions of Interest를 구한다 → Rol를 ROI pooling layer를 이용하여 고정된 크기로 변환하고, CNN을 진행한다
Conv 먼저하고 region proposals 얻을 때의 장점: 중복 연산 불 필요, CNN연산 재사용 가능함
문제(problem): Test time의 수행시간이 region proposals에 따라서 달라진다.
Faster R-CNN
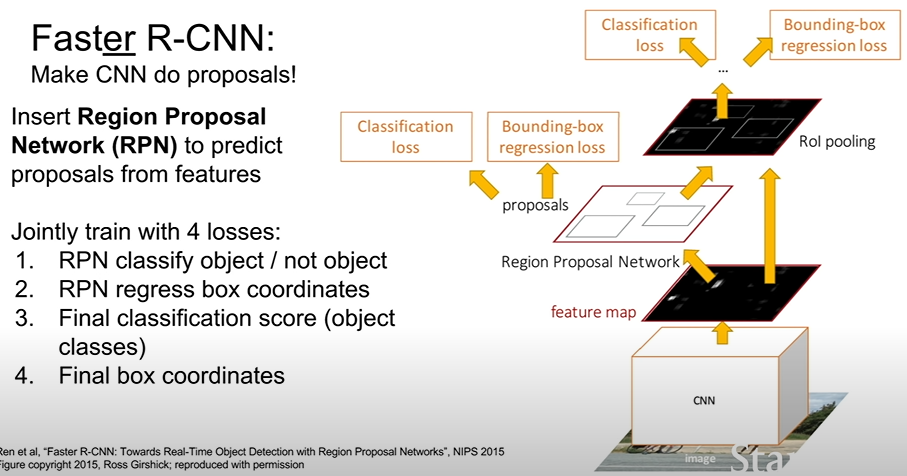

Fast R-CNN 보다 빨라졌다
Region Proposal도 fixed function이 아닌 Region Proposal Network를 이용해 예측하는 방식이며,
Region Proposal를 사용하지 않는 Network이다.
'Group Study (2022-2023) > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 5주차 스터디 - PART 2: Basic Deep Learning (0) | 2022.11.18 |
|---|---|
| [Machine Learning] 6주차 스터디 - Object Detection: YOLOv1~v2 (0) | 2022.11.15 |
| [Machine Learning]4주차 스터디 - ResNet 논문 요약 및 코드실습 (0) | 2022.11.04 |
| [Machine Learning] 3주차 스터디 - CNN의 이해(3) (0) | 2022.11.01 |
| [Machine Learning] 3주차 스터디 - Softmax Regression (0) | 2022.10.31 |