CNN
경계를 잘 분류한다. 그 이상의 구체적인 분류도 가능하다. 그 경계 상자만 찾는 것이 아니라 모든 픽셀에 대한 레이블을 지정할 수도 있다.
얼굴 인식 가능, 포즈 인식 가능, 게임에서의 강화 학습에 사용된다. 의료 이미지의 해석 및 진단, 은하 분류, 거리 표지판 분류, 고래 인삭(Kaggle Challenage), 거리 분류, 사진을 찍고 특정 화가의 이미지로 다시 이미지화(Redraw)에도 사용된다.

How CNN Works
Fully Connected Layer(FC)

만약에 32 * 32 * 3 이미지가 들어왔을 때, 이를 3072차원의 벡터로 변경시킨다.이미지들의 픽셀들을 다 일렬로 나열시킨다고 볼 수 있을듯? 강의에서는 strectch to 3072 * 1이라고 표현. 그렇게 된다면 1 * (32 * 32 * 3)의 값이 될 것이다. 3072차원의 벡터로 변경시킨다.
-> 10개의 가중치가 있다고 한다면 input(1 * 3072) * Weight(3072 * 10) (내적 곱을 통해서 구함)
-> activation(output of this layers)(1 * 10) 뉴런 output은 10개를 가지게 될 것이다.
Convolution Layer
Fully Connected Layer와의 차이점은 Fully Connected 의 경우 3차원으로 입력을 받아도 결국 하나의 긴 벡터로 펼친 후에 사용을 했는데, Convolution의 경우는 3차원 입력값을 그대로 사용한다.

필터의 너비와 높이의 크기는 입력보다 작을지라도 높이는 동일해야됩니다. 이 필터는 가중치가 된다.

이 필터를 가지고 처음부터 stride만큼 이동을 하면서 이미지의 공간 위치 위에 오버레이를 한 다음 내적을 계산한다. 필터와 이미지의 작은 5*5*3의 작은 청크 사이의 내적 곱이 필터와 이미지 청크를 펼쳐서 계산한 값과 같다.

이렇게 계산된 하나의 값이 있는데, 필터를 한 칸씩 이동을 하면서 해당 이미지 청크와 합성곱을 구하고, 이렇게 해서 activation map이 생기게 된다.



필터를 다르게 해서(색깔이 다른 것을 통해서 확인할 수 있다.) 여러 개의 activation maps가 생긴것을 확인할 수 있다.
결론적으로 28 * 28 * 6인 새로운 이미지를 쌓은 것을 확인할 수 있다.

최종적으로 ConvNet은 Convolution Layers의 연속으로 이루어져 있는데 중간중간 렐루를 가지고 있는 것을 확인할 수 있다.
렐루 함수란 시그모이드처럼 활성화함수긴 하지만 시그모이드의 경우는 0~1로 값을 바꾸어주지만 이는 시간이 너무 오래 걸리기 때문에 이미지 처리에는 주로 렐루 함수를 사용한다고 합니다. 렐루 함수는 음수인 경우는 0으로, 양수인 경우는 그냥 똑같은 값으로 출력을 해주는 함수입니다.
Stride
stride = 1





stride = 2



stride = 3
딱 맞아떨어지지 않으므로 3 * 3필터를 적용할 수 없다.
Output Size = (이미지의 가로/세로 - 필터의 가로/세로) / stride + 1
Padding

일반적으로 가운데 원본 이미지 픽셀 주변에 0으로 채우는 것을 패딩이라고 한다. 필터를 사용할 때마다 이미지의 크기는 점점 작아지게 된다. 하지만 우리는 이미지의 원래 크기를 보존하고 싶어하기 때문에 이미지 크기가 줄어드는 것을 막기 위해서 주변에 패딩을 넣어줍니다.
Pooling Layer

Max Pooling의 경우는 필터의 크기 안에서 값이 가장 큰 값을 가져오는 형식으로 진행이 된다.
풀링층을 만드는 이유는 층의 크기를 작고 다루기 쉽게 만들기 위해서 입니다. 강의 질문중에 stride를 수정해서 겹치게 할 수는 없냐는 질문이 있었는데, 일반적으로는 겹치지 않게 stride를 설정하는 것이 일반적이라고 했다. 애초에 풀링을 한다는 의미는 downsampling을 하는 것이기 때문이다.
다른 질문으로는 왜 Avg Pooling 보다 Max Pooling을 더 자주 사용하냐는 질문이었다. 그 이유는 우리가 풀링을 통해서 다운샘플링 분만이 아니라 나타나려는 것을 확실히 알 수 있는 것에도 도움을 받기 때문에 굳이 평균보다는 Max값을 사용하는 것이 확실한 특징을 얻을 수 있다고 했다.
Conv Layers Summarize

발표 자료

CNN Architectures
AlexNet
2012년에 도입된 최초의 Large scale CNN 모델이다. 8 layers를 사용하였다.

기본구조는 Convolution layer, Max Pooling Layer, Normaliztion이 2번 반복된 다음, 3번의 Convolution layer, 1번의 MaxPooling을 거친 후, 3번의 Fully Connected Layer가 나온다.
당시 당시 GPU 메모리가 32GB 한계로 모델을 두 파트로 나누어 계산했다.
VGGNet
2014년도 ImageNet Challenge에서 Google의 GoogLenet 다음으로 성능이 우수하고 강력한 네트워크를 가지고 있다.

19 layers를 사용해서 2013년에 비해서 훨씬 더 깊어진 네트워크를 확인할 수 있다.
기본 구조는 앞에 8개의 레이어는 AlexNet을 사용하고 있고, 16-19 레이어는 VGGNet을 사용하였다. 특징으로는 3 * 3 Conv stride 1, pad 1과 2 * 2 MAX POOL stride 2만 사용한 것이다. 3 * 3 Conv stride의 경우는 7 * 7 Conv layer와 같은 유효 수용 필드를 갖는다. 하지만 3 * 3이 유용한 잉는 더 깊은 네트워크를 가지면서 동시에 적은 매개변수를 사용하기 때문이다.
GoogleNet
2014년 Classification Challenge에서 우승한 GoogLeNet은 22개 층으로 네트워크는 더 깊어졌고 연산 효율은 증가했다.

기본 구조는 Stem Network(Conv-Pool-2xConv-Pool)이후에 Inception Modules를 가지고 있다. 가 스이에 보조 분류기가 있는데 AvgPool-1x1Conv-FC-FC-Softmax로 구성된 층이다. 보조 분류기는 일종의 mini network로 대표적으로 Average Pooling이 있다. 마지막에 Classifer Output으로 구성되어 있다. 이 mini network를 통해서 과적합을 해소할 수 있다고 한다.
Inception Modules란

구조로 되어 있다. 처음에는 왼쪽 모듈로 고안이 되었으니 이는 너무 많은 계산을 요구하기 때문에 bottleneck layers(1*1 Conv)를 사용해서 Previous Layers Depth를 줄여 그나마 계산이 줄어들 수 있도록 오른쪽처럼 고안을 했다.
ResNet
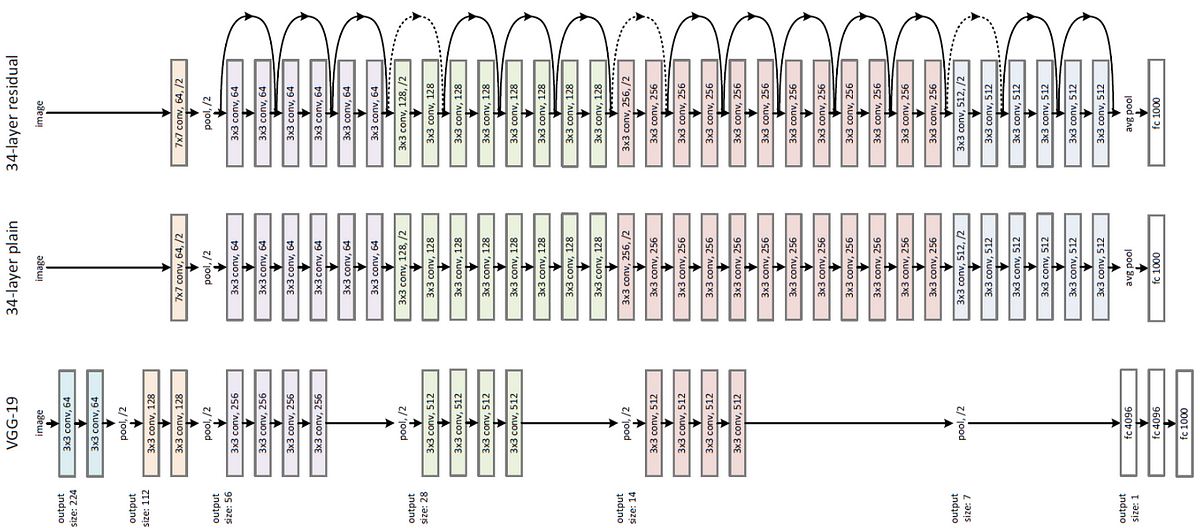
152 Layers를 가지고 있으며 ImageNet Challenage와 COCO에서 둘다 우승하였다.
사실 레이어가 50개가 넘어가게 된다면 20개의 층을 사용한 것 보다 오히려 안좋은 성능을 가지게 된다. 최적화 문제 때문이다.

오른쪽 그림은 ResNet의 Residual Block 구조이다. ResNet은 Block 단위로 파라미터를 전달하여 결론적으로 conv 층을 통과한 F(x)와 conv층을 통과하지 않은 x의 합을 논문에서는 Residual Mapping이라고 했다. 이를 통해서 여러 층을 쌓게 되면서 발생했던 과적합, 손실 등의 문제점을 해결하는데 도움이 되었다.
Comparing Complexity

왼쪽 차트 -> 성능이 가장 좋은 모델은 ResNet + Inception을 합친 모델이다.
오른쪽 차트 -> x 축은 작업량을 뜻하며 오른쪽으로 갈수록 작업량이 많다는 뜻이고, y축은 정확도이며 높을수록 좋은 것이다. 원의 크기는 클수록 메모리 양이 많다는 의미이다.
'Group Study (2022-2023) > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 5주차 스터디 - Object Detection: -stage-detector (0) | 2022.11.13 |
|---|---|
| [Machine Learning]4주차 스터디 - ResNet 논문 요약 및 코드실습 (0) | 2022.11.04 |
| [Machine Learning] 3주차 스터디 - Softmax Regression (0) | 2022.10.31 |
| [Machine Learning] 4주차 스터디 - Application & Tips (0) | 2022.10.31 |
| [Machine Learning] 2주차 스터디 - Multi variable linear regression & Logistic Regression (0) | 2022.10.10 |