아파치 카프카(Apache Kafka)란?
애플, 페이팔, 우버, 넷플릭스, 스포티파이 등 수많은 글로벌 기업에서 사용하는 빅데이터 처리를 위한 분산 스트리밍 플랫폼이다.

아파치 카프카는 빅데이터 시대의 서비스를 지탱하는 훌륭한 오픈소스로 자리잡았다. 분산 스트리밍 플랫폼으로 운영되는 아파치 카프카는 빅데이터 플랫폼뿐만 아니라 MSA(Microservice Architecture) 구조의 백엔드 아키텍처에서도 중요한 역할을 하고 있다.
Befor Kafka
- 간단한 단방향 통신에서 시간이 지날수록 Source Application과 Target Application이 많아지면서 데이터를 전송하는 라인이 많아지고 복잡해짐
- 데이터를 전송하는 라인이 많아지면 배포와 장애에 대응하기 어려워짐
- 데이터 변경이 있을 때 유지보수가 힘들어짐
After Kafka
- Source Application과 Target Application의 결합도를 약하게 하기 위해 개발
왜 아파치 카프카를 사용할까?
기존 AMQP와 다른 특징을 가진 스트리밍 플랫폼
브로커에 저장한 메시징 데이터는 처리 후 삭제되지 않고 저장되기 때문에 데이터를 재사용하는데 특화되어 있다.
서버에서 이슈가 생기거나 갑자스럽게 전원이 내려가는 상황에서 데이터를 손실없이 복구 할 수 있다.
이외에도 파티셔너, 리텐션, ISR과 같은 개념과 같은 카프카만의 특징이 있다.
TOPIC
- 데이터가 들어갈 수 있는 공간
- 파일 시스템의 폴더와 유사한 성질을 지님
- 하나의 토픽은 여러개의 파티션으로 구성
- Partition의 데이터 삭제되는 타이밍은 옵션에 따라 다름

Broker
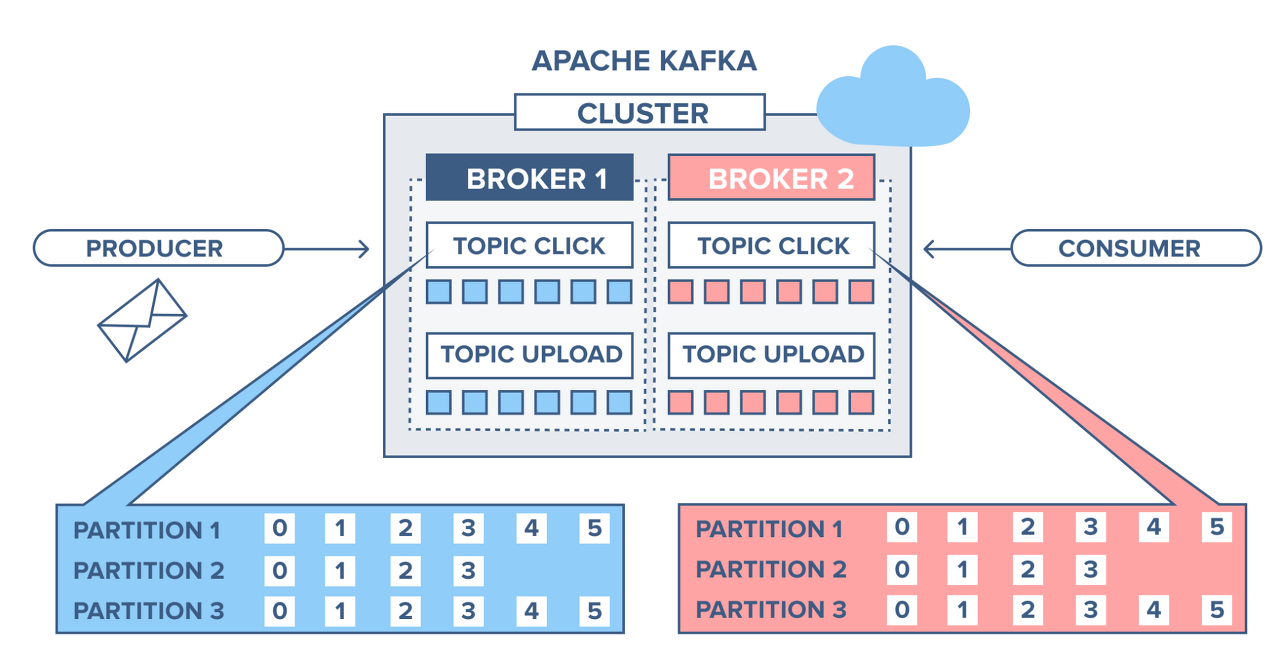
Replication

'GDSC Sookmyung 활동 > 10 min Seminar' 카테고리의 다른 글
| Spring Batch 알아보기 (0) | 2023.03.20 |
|---|---|
| MSA, 마이크로 서비스 아키텍처 (0) | 2023.03.19 |
| AI코딩 (1) | 2023.03.13 |
| 빅데이터를 알아보자 (0) | 2023.03.13 |
| GIT 브랜치 전략이란 (0) | 2023.03.05 |