Spring Batch란?
Spring Batch는 대량의 데이터를 처리하기 위한 오픈소스 batch processing 프레임워크이며, 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등 대용량 레코드 처리에 필수적인 기능을 제공합니다. 또한 최적화 및 파티셔닝 기술을 통해 대용량 및 고성능 배치 작업을 가능하게 하는 고급 기술 서비스 및 기능을 제공합니다.
Spring Batch는 간단하고 직관적인 프로그래밍 모델을 제공하며, 스프링 생태계의 다른 기술과의 통합도 용이합니다. 이를 통해 개발자는 빠르고 쉽게 배치 작업을 개발할 수 있습니다.
Spring Batch의 구성 요소

Spring Batch는 크게 Job, Step, Chunk, ItemReader, ItemProcessor, ItemWriter, JobRepository, JobLauncher로 구성되어 있습니다.
- Job: 배치 처리 과정을 하나의 단위로 만들어 놓은 객체입니다. 하나 이상의 Step으로 구성됩니다.
- Step: Job의 배치처리를 정의하고 순차적인 단계를 캡슐화합니다. 각 Step은 Job을 구성하는 독립적 작업의 단위입니다. ItemReader, ItemProcessor, ItemWriter로 구성됩니다.
이때 Step은 Tasklet과 Chunk 기반 2가지로 나눌 수 있습니다.
- Tasklet: Step이 중지될 때까지 execute 메서드가 계속 반복해서 수행되고 수행할 때마다 독립적인 트랜잭션이 얻어집니다.
- Chunk: 한 번에 하나씩 데이터(row)를 읽어 Chunk라는 덩어리를 만든 후, Chunk 단위로 트랜잭션을 다룹니다. 따라서 Chunk는 처리되는 commit row 수를 의미합니다.
- chunk 단위로 Transaction을 수행하기 때문에 실패시 Chunk 단위 만큼 rollback이 되게 됩니다.
일반적으로 Spring Batch는 대용량 데이터를 다루는 경우가 많기에, Tasklet보다는 상대적으로 트랜잭션의 단위를 짧게 하여 처리할 수 있는 Chunk 지향 프로세싱을 이용합니다. 따라서 두 가지 중 Chunk 기반의 Step에 대해 자세히 알아보겠습니다.
Spring Batch는 배치 작업을 단계별로 처리하는데, 각 단계는 ItemReader, ItemProcessor, ItemWriter로 구성됩니다.
- ItemReader: 대량의 데이터를 읽어오는 역할을 합니다.
- ItemProcessor: ItemReader에서 읽어온 데이터를 가공하는 역할을 합니다.
- ItemWriter: 가공된 데이터를 저장하는 역할을 합니다.
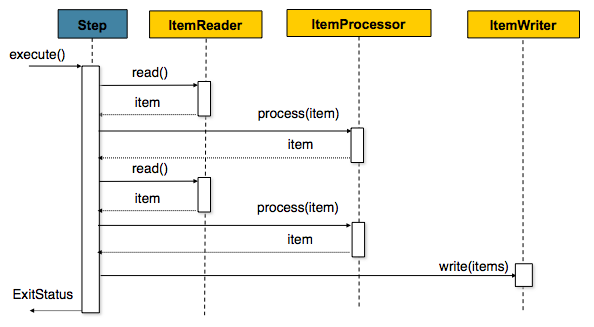
- JobRepository: Job과 Step의 상태를 유지 및 관리합니다. 실행된 Step, 현재 상태, 읽은 아이템 및 처리된 아이템 수 등이 모두 여기에 저장됩니다.
- JobLauncher: Job을 실행하고, 완료되면 JobExecution 정보를 반환합니다. 스프링부트의 환경에서는 부트가 Job을 시작하는 기능을 제공하여 일반적으로는 직접 다룰 필요가 없는 컴포넌트입니다.
왜 Spring Batch를 사용해야 하나요?
Spring Batch는 대량의 데이터를 처리할 때 매우 유용합니다. 예를 들어, 금융 거래 내역, 주문 정보 등 대량의 데이터를 처리해야 하는 경우 Spring Batch를 사용하면 편리합니다. Spring Batch의 장점은 다음과 같습니다.
- 대용량 데이터 처리: 대규모 데이터 처리를 위한 프레임워크로, 대용량 데이터를 효율적으로 처리할 수 있습니다. 이를 통해 성능이 향상되고, 시스템의 확장성이 높아집니다.
- 표준화된 개발 모델: 표준화된 개발 모델을 제공하며, 이를 통해 개발자는 일관된 방식으로 배치 작업을 개발할 수 있습니다. 이는 코드 유지 보수성을 높이고, 개발 생산성을 향상시킵니다.
- 다양한 데이터 소스 지원: 다양한 데이터 소스와의 연동을 지원합니다. 이를 통해 관계형 데이터베이스, NoSQL 데이터베이스, CSV 파일, XML 파일 등 다양한 데이터 소스에서 데이터를 읽어올 수 있습니다.
- 재시작 및 복구 기능: 작업 중 실패가 발생하면, 재시작 및 복구 기능을 제공합니다. 이를 통해 데이터 무결성을 보장하며, 배치 작업의 안정성을 높입니다.
- 모니터링 및 관리 기능: 배치 작업의 모니터링 및 관리를 위한 다양한 도구와 플러그인을 제공합니다. 이를 통해 배치 작업의 실행 상태를 모니터링하고, 성능 향상을 위한 통계 정보를 수집할 수 있습니다.
- 스프링 프레임워크와 통합: 스프링 프레임워크와 통합되어 있습니다. 이를 통해 스프링의 다른 기능과 함께 사용할 수 있으며, 스프링 개발자들은 더욱 익숙한 개발 환경에서 배치 작업을 개발할 수 있습니다.
Spring Batch를 사용한 배치 처리 예제
Spring Batch
디자인 전문가가 아니어도 무료 템플릿으로 손쉽게 원하는 디자인을 할 수 있어요.
www.miricanvas.com
Spring Batch를 사용하여 배치 처리를 하는 예제를 살펴보겠습니다. 이 예제에서는 CSV 파일에서 데이터를 읽어와서, 데이터를 가공한 후 데이터베이스에 저장합니다.
1. 의존성 추가
Spring Batch를 사용하기 위해 다음 의존성을 추가합니다.
dependencies {
...
implementation 'org.springframework.boot:spring-boot-starter-batch'
...
}2. 메인 클래스에 @EnableBatchProcessing 어노테이션 설정
@EnableBatchProcessing
@SpringBootApplication
public class SpringBatchApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBatchApplication.class, args);
}
}3. Job과 Step 생성
@Slf4j
@RequiredArgsConstructor
@Configuration
public class SimpleJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final CsvReader csvReader;
private final AcademyProcessor academyProcessor;
private final ClassProcessor classProcessor;
private final AcademyWriter academyWriter;
private final ClassWriter classWriter;
private static final int chunkSize = 100;
@Bean
public Job csvFileItemReaderJob(){
return jobBuilderFactory.get("csvFileItemReaderJob")
.start(csvFileItemReaderStep1())
.next(csvFileItemReaderStep2())
.build();
}
public Step csvFileItemReaderStep1() {
return stepBuilderFactory.get("csvFileItemReaderStep1")
.<CsvDto, Academy>chunk(chunkSize)
.reader(csvReader.csvFileItemReader())
.processor(academyProcessor)
.writer(academyWriter)
.build();
}
public Step csvFileItemReaderStep2() {
return stepBuilderFactory.get("csvFileItemReaderStep2")
.<CsvDto, Classroom>chunk(chunkSize)
.reader(csvReader.csvFileItemReader())
.processor(classProcessor)
.writer(classWriter)
.build();
}
}이 예제에서는 하나의 csvFileItemReaderJob에서 총 2개의 Step을 실행하고 있습니다. Job에서는 next 설정을 통해 순차적으로 Step을 실행시킬 수 있습니다. 이외에도 from, on, to, end 등으로 다양한 설정을 통해 step 분기를 설정할 수 있습니다.
Step에서는 reader, processor, writer를 통해 파일을 처리하고 있습니다. Step1을 예시로 살펴보면, chunk 앞의 csvdto, academy는 각각 input과 output을 의미합니다. 따라서 csvReader에서 csvdto 형식으로 파일을 읽어들이고, 최종적으로 writer에서 Academy 클래스 형식으로 파일을 써내려갈 것임을 알 수 있습니다.
4. ItemReader 생성
이 예제에서는 CSV 파일에서 데이터를 읽어오기 때문에, FlatFileItemReader를 사용합니다.
@Configuration
@RequiredArgsConstructor
public class CsvReader {
@Bean
public FlatFileItemReader<CsvDto> csvFileItemReader() {
/* file read */
FlatFileItemReader<CsvDto> flatFileItemReader = new FlatFileItemReader<>();
flatFileItemReader.setResource(new ClassPathResource("/academyInfo.csv"));
flatFileItemReader.setLinesToSkip(1); // header line skip
flatFileItemReader.setEncoding("UTF-8"); // encoding
/* read하는 데이터를 내부적으로 LineMapper를 통해 Mapping */
DefaultLineMapper<CsvDto> defaultLineMapper = new DefaultLineMapper<>();
/* delimitedLineTokenizer : setNames를 통해 각각의 데이터의 이름 설정 */
DelimitedLineTokenizer delimitedLineTokenizer = new DelimitedLineTokenizer(",");
delimitedLineTokenizer.setNames("academy_name", "region", "address", "tel", "month_tuition", "teacher", "elem_grade", "mid_grade", "high_grade", "else_grade", "class_name");
delimitedLineTokenizer.setStrict(false); // csv 파일의 컬럼과 불일치 허용
defaultLineMapper.setLineTokenizer(delimitedLineTokenizer);
/* beanWrapperFieldSetMapper : Tokenizer에서 가지고 온 데이터들을 바인드하는 역할 */
BeanWrapperFieldSetMapper<CsvDto> beanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper<>();
beanWrapperFieldSetMapper.setTargetType(CsvDto.class);
defaultLineMapper.setFieldSetMapper(beanWrapperFieldSetMapper);
/* lineMapper 지정 */
flatFileItemReader.setLineMapper(defaultLineMapper);
return flatFileItemReader;
}
}5. ItemProcessor 생성
ItemProcessor는 ItemReader에서 읽어온 데이터를 가공합니다.
@Configuration
@RequiredArgsConstructor
public class AcademyProcessor implements ItemProcessor<CsvDto, Academy> {
@Override
public Academy process(CsvDto item) throws Exception {
Academy result = new Academy();
// 학원 정보 추출
result.setAcademyName(item.getAcademyName());
result.setRegion(item.getRegion());
result.setAddress(item.getAddress());
result.setTel(item.getTel());
result.setTeacher(item.getTeacher());
result.setElem_grade(item.isElem_grade());
result.setMid_grade(item.isMid_grade());
result.setHigh_grade(item.isHigh_grade());
result.setElse_grade(item.isElse_grade());
return result;
}
}6. ItemWriter 생성
ItemWriter는 가공된 데이터를 저장합니다.
@Configuration
@RequiredArgsConstructor
public class AcademyWriter implements ItemWriter<Academy> {
private final AcademyRepository academyRepository;
@Override
public void write(List<? extends Academy> list) throws Exception {
for (Academy academy : list) {
Optional<Academy> temp = academyRepository.findByAcademyName(academy.getAcademyName());
if (!temp.isPresent()) {
academyRepository.save(academy);
}
}
}
}
결론
이상으로 Spring Batch에 대해 알아보았습니다. Spring Batch는 대량의 데이터를 처리할 때 안정성과 성능을 보장하며, 여러 가지 유용한 기능을 제공합니다. Spring Batch는 다양한 실행환경에서 사용할 수 있으며, 개발자들은 Spring Batch를 쉽게 사용할 수 있기 때문에, 대량의 데이터 처리가 필요한 프로젝트에서 Spring Batch를 고려해보는 것이 좋습니다.
'GDSC Sookmyung 활동 > 10 min Seminar' 카테고리의 다른 글
| 블록체인과 암호화폐 (0) | 2023.03.27 |
|---|---|
| Tailwind CSS + CSS Resource (0) | 2023.03.20 |
| MSA, 마이크로 서비스 아키텍처 (0) | 2023.03.19 |
| Apache Kafka 알아보기 (0) | 2023.03.13 |
| AI코딩 (1) | 2023.03.13 |