4월 3주차 GDSC Sookmyung Weekly AI Trend

Segment? 나에게 맡기라구! 😋
Meta의 Segment Anything Model
에디터 | 조유림
META에서 ‘Segmentation Anything Model(SAM)’과 ‘Segment Anything 1-Billion mask Dataset(SA-1B)을 공개하였습니다. SAM은 객체에 대한 일반적인 개념을 학습하고, 이미지나 영상의 어떤 객체에 대해서도 마스크를 생성할 수 있습니다. 말 그대로 ‘Segment Anything’, 즉 무엇이든, 어떤것이든 Segment 해준다는 것입니다. 다음은 META 기술 블로그에서 소개한 SAM의 내용입니다.
SAM: A generalized approach to segmentation
우선, Segment Task에서 대표적인 2가지 접근법은 다음과 같습니다:
- Interactive segmentation
- Automatic segmentation
Interactive segmentation 접근법은 사람이 분할 과정을 안내하는 데 가이드라인을 제공합니다. 사용자가 이러한 내용을 입력으로 주면, 반복을 통해 알고리즘을 개선합니다. 모든 종류 객체를 분할하는 데 유용하지만, 사람의 참여로 시간이 오래 걸린다는 단점이 있습니다.
Automatic segmentation 접근법은 사람이 별도로 가이드라인 입력을 하지 않아도 머신 러닝 알고리즘에 의존하여 학습을 진행하는 방식입니다. 이 경우에는 이미 분할된 라벨링 이미지의 대규모 데이터셋에서 훈련되는 경우가 많습니다. 이러한 방식을 통해 학습할 경우, 1번 방식보다 빠르고 확장성을 가지고 있으나, 데이터셋의 크기가 상당히 커야하고, 훈련되지 않은 클래스에 대해 일반화하기 어렵다는 단점이 있습니다.
SAM의 경우 각각의 접근법의 장점을 따와 일반화된 분할 접근 방식으로, 하나의 모델이 두 가지 작업을 유연하고 효율적으로 수행할 수 있습니다. 10억 개 이상의 high-quality 데이터 세트로 학습되었으며, 훈련 중 관찰되지 않은 새로운 유형에 대해 일반화가 가능합니다.
How SAM works: Promptable segmentation
그렇다면 SAM은 어떻게 동작할까요? SAM은 프롬프팅(prompting) 기술을 사용하며, zero-shot 및 few-shot learning을 기반으로 설계되었습니다. 사전 훈련 되어 프롬프팅을 통해 segmentation task를 수행합니다.
SAM의 이미지 인코더는 이미지에 대한 일회용 임베딩(one-time embeddings)을 생성하고, lightweight encoder는 프롬프트 임베딩으로 변환합니다. lightweight mask decoder는 세분화 마스크를 예측하며, 이미지 임베딩이 계산되면 SAM은 웹 브라우저에서 모든 프롬프트에 대해 segmentation을 빠른 속도로 생성할 수 있습니다. 아래는 아키텍쳐 이미지입니다.
Segmenting 1 billion masks: How we built SA-1B
META에서는 SA-1B 데이터셋 구축을 위해 SAM을 사용했습니다. SAM을 사용하여 이미지에 대해 주석을 달고, 새롭게 주석이 달린 데이터를 SAM에 업데이트하는 방식을 반복하여 모델과 데이터셋을 개선했다고 합니다.
Reference
- https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
LLM에 관한 8가지 사실
에디터 | 정시은
최근 몇달간 ChatGPT와 같이 LLM을 기반으로 만들어진 제품의 배포는 다양한 분야의 학자들에게 폭발적인 관심을 받고있습니다. 따라서 이번주는 4월 첫째주에 Top ML Papers of the Week에 올랐던 “잠재적으로 주목할만한 LLM에 관한 8가지 사실”에 대한 논문을 요약해 드리려 합니다. 이 논문은 LLM의 안전 및 제어, 내부 작업 해석의 어려움, LLM이 특정 작업에서 인간을 능가할 가능성에 대한 우려를 포함하여 LLM에 대해 알아야 할 8가지 핵심 사항에 대해 설명합니다. 또한 이 논문은 LLM을 연구할 때의 한계와 과제를 강조하고 LLM이 더 강력해지고 광범위하게 배포됨에 따라 안전의 표준과 감독을 강화해야 할 필요성을 강조합니다.
여기서 LLM이란?
LLM (large language model)은 다량의 데이터에서 얻은 지식기반 콘텐츠나 텍스트를 인식, 요약, 번역, 예측, 생성할 수 있는 딥러닝 알고리즘입니다.
What Are Large Language Models Used For? LLM은 어디에 사용될까요 ?
LLM은 다양한 유형의 의사소통이 필요한 언어에 적용될 수 있습니다.예를 들어, LLM을 사용하는 AI 시스템은 분자 및 단백질 구조의 데이터베이스에서 학습한 다음, 그 지식을 사용하여 과학자들이 획기적인 백신 또는 치료법을 개발하는 데 도움을 제공할 수 있습니다. 또한, 재설계된 검색 엔진, 챗봇 교육, 노래, 시, 이야기 및 마케팅 자료를 위한 구성 도구 등을 만드는 데 도움이 됩니다.
How Do Large Language Models Work? LLM은 어떻게 동작할까요?
LLM은 방대한 양의 데이터로부터 학습합니다. 이름에서 알수있듯이 LLM의 핵심은 훈련된 데이터의 크기입니다. 이러한 방대한 양의 텍스트는 비지도 학습을 사용합니다. LLM은 특정 사용사례에 맞게 사용자 지정할 수 있으며, 모델에 초점을 맞출 작은 데이터 비트를 제공하여 특정 애플리케이션에 맞게 훈련시키는 프로세스인 fine tuning과 prompt tuning이 포함됩니다. .
그럼 본격적으로 LLM에 대해 알아야할 8가지 사실에 대해 알아보도록 합시다!
1. LLM에 대한 투자는 급증하고 있습니다.
‘Scaling Law’ 는 data, size, computation 이 세가지 차원을 따라 모델이 확장될때 모델의 기능을 정확하게 예측할 수 있다고 합니다. 그 덕분에 연구와 투자가 급증하고 있는데요. 이러한 예측할 수 있는 능력은 소프트웨어 및 AI 연구 역사에서 이례적이며 투자를 촉진하는 강력한 도구라고 합니다.
2. LLM에게서 보여지는 특정 행동은 예측할 수 없이 나타납니다.
앞서 말한 Scaling법칙은 일반적으로 모델의 pretraining test loss(불완전한 텍스트가 계속되는지 예측)만 예측합니다.
아래 그림은 이 척도가 모델이 실제 작업에서 평균적으로 얼마나 유용한지와 관련이 있지만, 모델이 특정 작업을 수행할 수 있게 될 시기를 예측하는 것은 대체로 불가능하다는 것을 말해줍니다. 경제적으로 가치가 있는 다양한 새로운 기능을 얻을 수 있을 것이라고 확신할 수 있지만, 이러한 기능이 무엇인지 또는 그 기능을 책임감 있게 구현하기 위해 어떤 준비가 필요한지에 대해서는 확신할 수 없음을 뜻한다고 할 수 있겠죠.
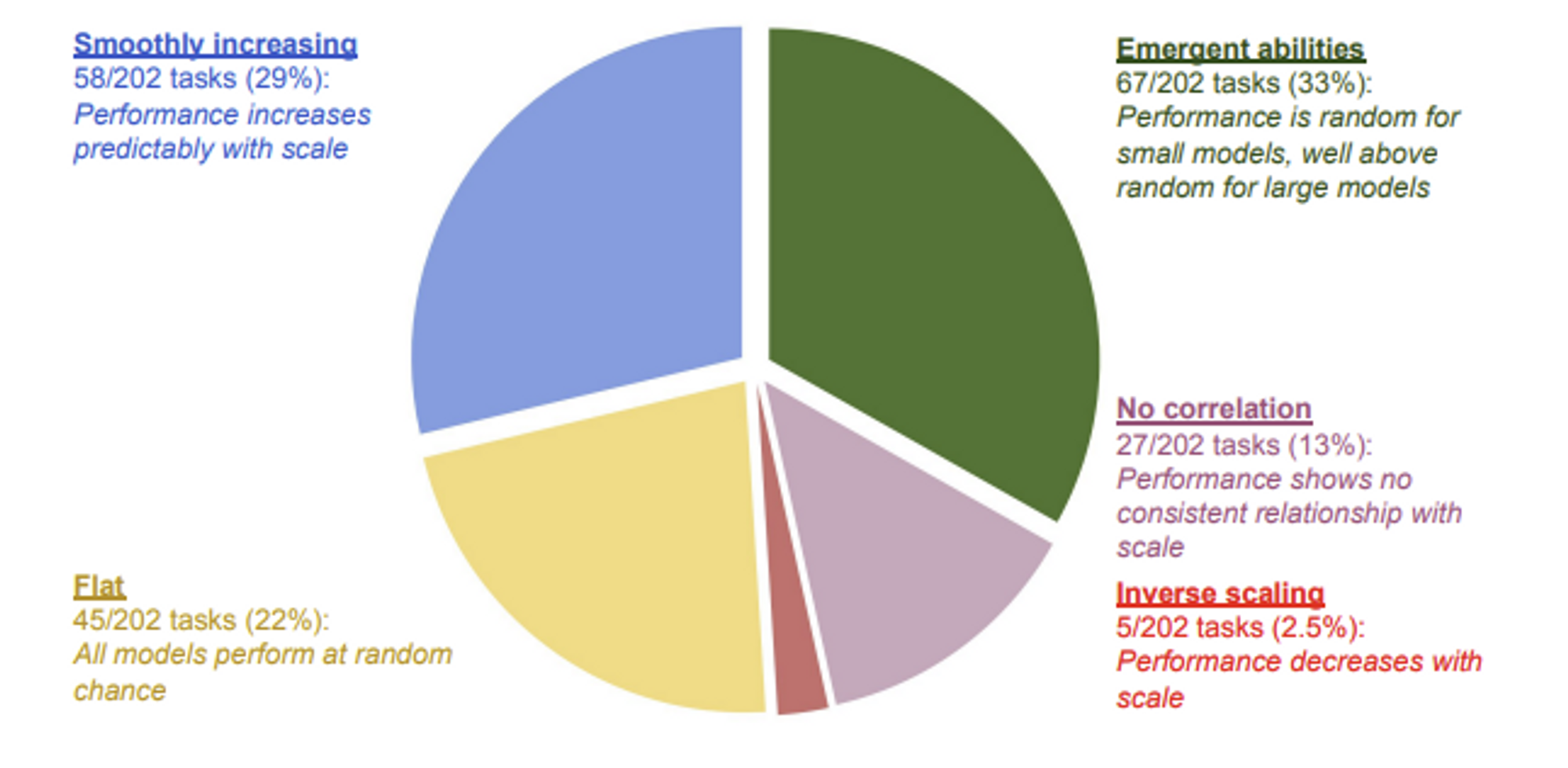
또한, 미래의 LLM에서 나타날 수 있는 기능에 대해서는 합의된 제한이 거의 없습니다. 현재 LLM의 동작에는 몇가지 제약이 있지만(한번에 입력으로 사용할 수 있는 텍스트의 양, 훈련중에 세상과 상호작용할 수 있는 능력, 생성된 단어에 대해 수행할 수 있는 계산), 추가 연구를 통해 이를 극복할 가능성이 있습니다.
3. LLM은 종종 외부 세계의 표현을 배우고 사용하는 것처럼 보입니다.
LLM은 internal representation(내재적 표현, 컴퓨터가 픽셀에 심어진 숫자정보를 이용해서 인간적인 표현을 특정하는것을 의미합니다, 예를들어 이미지를 보고 고양이라고 인식하는것을 생각하시면 됩니다!)을 추상적인 수준에서 추론할 수 있는 수준으로 발전하고 있습니다. 이 현상에 대한 증거로는 모델의 색상 단어에 대한 내재적 표현, 문서 작성자가 알고 있거나 믿는 것에 대한 추론 능력, 이야기에 설명된 객체의 속성과 위치에 대한 내재적 표현 사용 등이 있습니다. 이러한 내재적 표현은 LLM이 statistical next-word predictor일 뿐이라는 보편적인 의견과 대립되며 LLM은 세계에 대한 다양한 학습 방법으로 점점 더 강화되고 있습니다.
4. LLM의 동작을 제어하는 신뢰할 수 있는 기술이 없습니다.
큰 모델이 일반화를 더 잘 학습하지만 특정 상황에서 예기치 않게 행동할 가능성이 높아 안전과 잠재적인 재앙적 결과에 대한 우려가 더 큽니다. 많은 연구원들은 대규모 LLM 훈련이 계속되기 전에 적절한 안전 및 정부의 지침이 마련되어야 한다고 생각합니다.
5. 전문가들은 아직 LLM의 내부 작동을 해석할 수 없습니다.
인공 신경망에 구축된 현대 LLM의 동작을 이해하는 데에는 어려움이 따릅니다. 모델들이 어떻게 작동하는지를 밝혀내기 위한 연구가 진행 중인 동안, 인공 뉴런들의 복잡한 연결은 그들의 행동에 대한 정확한 설명을 제공하는 것을 어렵게 만듭니다. 통찰력을 제공하는 것처럼 보이는 임시 기술은 오해의 소지가 있을 수 있으며 모델 생성 설명도 체계적으로 오해의 소지가 있을 수 있습니다.
6. 특정 작업에 대한 인간의 성과가 LLM 성과보다 높다고 할 수 없습니다.
인간의 글쓰기 행동을 모방하도록 훈련된 LLM이 방대한 양의 데이터에 대해 훈련되고 강화 학습을 받을 수 있기 때문에 특정 작업에서 인간을 능가할 수 있는 가능성이 존재합니다. LLM은 주어진 텍스트 뒤에 어떤 단어가 나타날 가능성이 가장 높은지 예측하는 데 있어 인간보다 우수한 것으로 나타났으며, 특정 작업을 인간보다 더 정확하게 수행하도록 가르칠 수 있습니다.
7. LLM은 작성자나 웹 텍스트로 인코딩된 값을 표현할 필요가 없습니다
일반적으로 사전 훈련된 LLM이 텍스트를 생성할 때 해당 텍스트는 훈련된 텍스트와 유사합니다. 여기에는 텍스트로 표현된 값의 유사성이 포함되는데, 이는 개발자에 의해 제어되고 영향을 받을 수 있습니다. 헌법 인공지능과 같은 기술을 사용하면 이러한 값을 더 명확하게 만들고 모델 행동에 대한 편견을 줄일 수 있습니다. 그러나 환경 영향, 접근, 오용, 개인 정보 보호, 안전 및 권력 집중과 관련된 문제를 포함하여 대규모 AI 시스템의 개발 및 배치를 둘러싼 윤리적 문제가 여전히 있습니다.
8. LLM과의 짧은 상호작용은 종종 오해의 소지가 있습니다.
LLM은 지침을 따를 수 있지만 이 동작은 고유하지 않으며 지침의 문구에 민감할 수 있습니다. 작업을 실패한 언어 모델은 해당 작업을 수행할 수 있는 기술이나 지식이 부족하다는 것으로 해석할 수 없으며, 한 번의 작업에서 성공한 언어 모델을 관찰하는 것 또한 일반적으로 해당 작업을 수행할 수 있다는 강력한 증거가 되지 않는다고 지적합니다.
Reference
- https://arxiv.org/abs/2304.00612v1
멀티모달 언어 모델: 인공지능의 미래
에디터 | 송지빈
대규모 언어 모델 LLM에 대해 알고 계신가요? 최근 Chat GPT 이슈로 인해 알고 계실 것 같은데요. 대규모 언어 모델(LLM)은 텍스트를 분석하고 생성할 수 있는 AI 모델입니다. 방대한 양의 텍스트 데이터로 학습되어 텍스트 생성, 심지어 코딩과 같은 분야에서 뛰어난 성능을 발휘합니다.
현재 대부분의 LLM은 텍스트만을 다룬 모델로, 텍스트 기반의 애플리케이션에서는 뛰어나지만, 이미지, 음성, 비디오 등 다른 유형의 데이터를 이해하는데 한계가 있습니다.텍스트 전용 LLM의 예로는 GPT-3, BERT, RoBERTa 등이 있습니다.
반면에, 멀티모달 언어모델은 텍스트와 함께 이미지, 비디오, 오디오 등과 같은 다른 유형의 데이터와 결합시킬 수 있습니다. 멀티모달과 언어모델을 통합하면서 현재의 텍스트만을 다루는 모델의 한계를 해결하고, 이전에는 불가능했던 다양한 애플리케이션의 확장이 가능할 것으로 기대됩니다.
Open AI에서 최근 출시된 GPT-4는 멀티모달 언어모델을 적용한 사례 중 하나입니다. 텍스트와 이미지를 모두 입력할 수 있고, 이는 인간 수준의 성능을 보여주었습니다.
멀티모달 AI의 등장
멀티모달 AI의 발전은 두 가지 중요한 머신러닝 기술 덕분이라고 할 수 있습니다. 바로 표현 학습과 전이 학습입니다. 표현 학습을 통해 모델은 이미지, 텍스트, 음성에 대해 특징을 추출하여 결합할 수 있고, 전이 학습을 통해 기존의 모델을 다양한 방식으로 활용하여 학습할 수 있습니다. 멀티모달 기술을 적용한 모델로는 CLIP, DALL-E 2, Stable Diffusion 등이 있습니다.
이미지, 텍스트, 음성, 비디오 등 서로 다른 유형간의 경계는 줄어들면서, 다양한 데이터들 간의 관계를 학습하여 활용하는 분야가 늘어날 것으로 예상됩니다. 즉, 한 유형의 데이터를 다루는 방식은 점차 사라질 것이고, 다양한 유형 간의 연관성 다루는 방식과 이를 이해하는 것의 중요성은 계속 커질 것입니다.
멀티모달 LLM를 적용한 사례
OpenAI: GPT-4
GPT-4는 이미지와 텍스트를 모두 입력받아 텍스트를 생성할 수 있는 대규모 멀티모달 모델입니다. 이전 모델인 GPT-3.5와 비교했을 때, 일상적인 대화에서는 두 모델 간의 차이가 미미할 수 있지만, 작업의 복잡성이 특정 수준에 도달하면 분명한 차이가 나타납니다.
최근 칸 아카데미에서는 학생들을 위한 가상 튜터와, 교사를 위한 수업 보조 역할을 하는 AI 비서 Khanmigo를 사용할 것이라고 밝혔습니다. 개념을 이해하는 학생들의 이해 능력이 모두 다양하기 때문에 GPT-4를 사용하면 더 좋은 학습 서비스를 제공할 수 있을 것입니다.
Microsoft: Kosmos-1
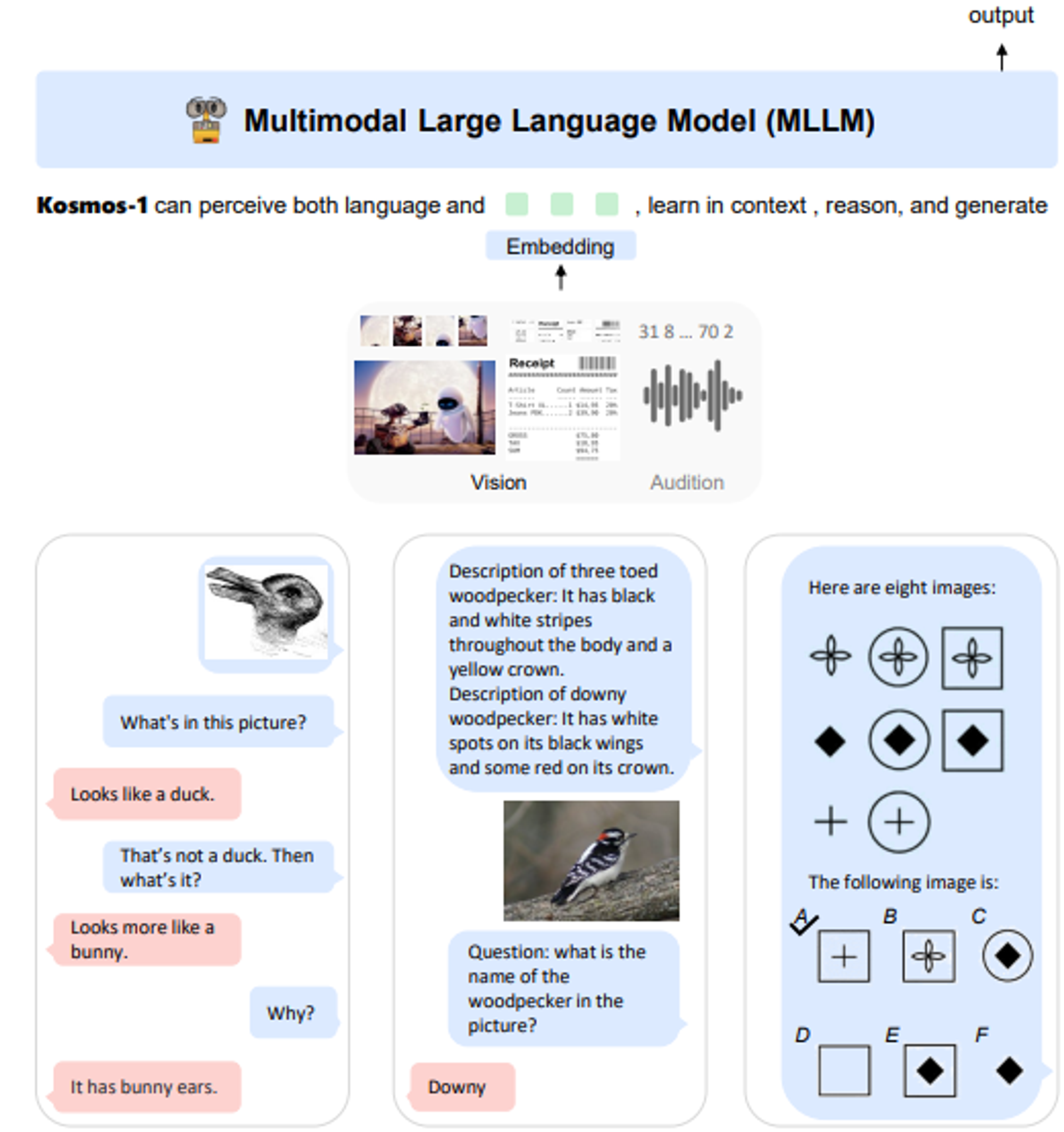

Kosmos-1은 웹 상의 텍스트, 이미지 데이터로 학습되어, 언어 이해, 생성, 시각-언어 인식 등 다양한 작업을 지원합니다.
Google: PaLM-E
PaLM-E는 Google과 베를린 공과대학교의 연구진이 개발한 새로운 로보틱스 모델입니다. 대규모 언어 모델인 ‘팜(PaLM)’에 감각 정보를 내장해 다양한 시각, 센서 데이터를 통합하여 사람처럼 보고, 듣고, 움직일 수 있는 로봇을 구현하였습니다.
이 모델은 ‘서랍에서 과자를 꺼내와’ 같은 복잡한 명령이 주어지면 언어 분석과 컴퓨터 비전을 기반으로 행동 계획을 생성합니다. 즉, 사람의 말을 이해한 뒤 카메라를 통해 보이는 주변 환경을 인식한 다음 실행 계획을 수립합니다. 그 과정에 시각 데이터를 처리하거나 별도의 주석을 다는 인간의 개입이 필요 없어 자율적인 거동이 가능합니다.

지금까지 멀티모달 LLM 기술과 이러한 기술을 적용한 사례에 대해 알아봤습니다. 멀티모달 LLM의 가능성은 무궁무진하며, 이제 그 진정한 잠재력을 탐구하기 시작했습니다. 엄청난 가능성을 고려할 때, 멀티모달 LLM이 AI의 미래에 중요한 역할을 할 것임은 분명합니다.
Reference
- Multimodal Language Models: The Future of Artificial Intelligence (AI)
- GPT-4 Technical Report 정리
- 구글, 사람처럼 보고 듣고 움직이는 '로봇 제어' 인공지능 공개
인공지능 판사에 대한 이슈
에디터 | 손수경
우리나라 판사의 절반 가량은 일주일에 세 차례 넘게 야근을 하고 주말에도 일하는 등 주 52시간 이상 일하는 것으로 나타났다. 국민의 재판 받을 권리를 충분히 보장과 사법서비스 질 개선과 사법신뢰 회복 측면에서 적정한 판사 증원이 시급하다는 지적이 나왔다.
최근 ChatGPT의 열풍으로 강민구 서울고등법원 부장판사는 ‘GPT 시대와 법조인의 대응자세’ 에 대한 주제로 강연했다. 이날 강 부장 판사는 “챗GPT가 간단한 사건 소장은 변호사 조력 없이 자동으로 작성할 수 있는 등 법조계 환경이 바뀔 것으로 예상”하고 있다고 하였다. 실제로 ChapGPT에게 “How ChatGPT can be used in the legal marketplace?” 라는 질문을 하였더니 “법률 연구, 법률 문서 생성, 법률 자문 및 지원, 고객 유입 및 분류, 법률 교육, 가상 법률 지원, 언어 번역 및 통역 등 다양한 방식으로 사용될 수 있다”고 하였다.
하지만 과연 ChatGPT와 같은 Generate Model이 사건에 대한 판단을 할 수 있을까?
이에 대한 몇 가지 이슈가 있다.
- 인공지능의 편견과 차별
2016년 미국 주 법원과 교도소에서 형량, 가석방 등에 사용하던 AI 알고리즘 컴퍼스COMPAS는 ‘흑인의 범죄율이 높을 것이다.’, ‘흑인의 재범 가능성은 백인보다 2배’라고 판단해 흑인들이 무고한 수감생활을 하게 했다. 이처럼 기계라고 더욱 신뢰를 할 수 있는 것은 아니다. AI 시스템은 의사 결정에서 편견과 차별을 영구화하거나 심지어 증폭시킬 수 있는 잠재력을 가지고 있다. 따라서 기업은 사용 중인 데이터의 잠재적 편향을 인식하고 이를 가지하고 수정하는 매커니즘을 구현해야 한다. - 투명성 및 설명 가능성
AI 시스템은 굉장히 복잡하기 때문에 불투명하고 이해하기 어려워 개인이 의사 결정이 어떻게 이루어지고 있는지 이해하기 어려울 수 있다. 따라서 기업은 AI 시스템이 내린 결정을 설명하고 공정성, 정확성 및 투명성에 대한 증거를 제공할 수 있도록 보장해야 된다. - 윤리적 이슈
인공지능의 윤리적 문제는 특정 집단에 대한 편견이나 에러를 통해서 발생하게 된다. AI는 AI가 고용에 미치는 영향, AI가 사회에 미치는 영향, AI가 유해한 목적으로 사용될 가능성과 같은 많은 윤리적 고려 사항을 제기한다. 하지만 현재까지는 인공지능에 대한 규제 법안이 없다. 다만 기존의 기술에 대한 법안과 규제(데이터 보호, 프라이버시)만 적용되고 있다. 기술이 정교하게 될수록 법안과 윤리적 이슈를 잘 고려해야 된다.
인공지능 법은 빠르게 발전하는 분야다. 결론적으로 AI가 편향되지 않고 윤리적인 방식으로 개발되고 사용될 수 있도록 법적, 규제적 프레임워크가 필요하다.
이러한 이슈들이 해결이 된다면 언젠가는 AI가 간단한 법적 문제는 해결할 수 있는 날이 오지 않을까?
Reference
- Legal issues related to AI according to ChatGPT
- 판사 절반, 주52시간 초과 근무…“재판 받을 권리 위해 증원 시급”
- Legal & ethical aspects of artificial intelligence, robotics & algorithms