4월 4주차 GDSC Sookmyung Weekly AI Trend

Generation Model 어디까지 활용될 수 있을까?
:: Generation Model 정의 및 ai-workout-assistant 모델 소개
에디터 | 손수경
Generation Model이란 무엇을 생성한다는 것일까?
주어진 학습 데이터를 학습하고 학습 데이터의 분포를 따르는 유사 데이터를 생성하는 모델이다. 즉, 주어진 training data와 같은 distribution을 가진 새로운 sample을 만들어내는 모델이다.
위 그림과 같이 생성 모델은 실제 세계의 데이터로부터 비슷한 Fake Data를 생성할 수 있다. 또한, Time series data 등은 생성 모델에서 시뮬레이션이나 Planning에 사용 가능하다.
Generation Model의 활용
학습 데이터를 활용해서 새로운 sample을 만든다는 특징 때문에 과거부터 이미지 생성, 스타일 변화, 이미지 복원 등 특정 이미지에 대해서 생성을 해주는 기능으로 많이 활용되었다. 하지만 이번 주에는 보다 활용된 기능을 만든 모델에 대해서 소개해줄 예정이다.
ai-workout-assistant github 👉🏻 https://github.com/reevald/ai-workout-assistant?linkId=8710070
해당 모델은 비디오나 웹캠으로부터 자세를 detect하여 주요 포인트들의 각도, 위치를 생성해주는 모델이다. 최근 헬린이가 된 입장에서 굉장히 유용한 모델이라는 생각이 든다. 허리의 각도, 다리 포복의 정도, 무릎의 각도 등은 헬스에서 굉장히 중요한 부분이다. 이를 PT쌤을 대신하여 집에서도 혼자 자세를 연습하고 확인해볼 수 있다는 점이 굉장히 끌렸던 것 같다.
더 나아가 이 모델을 보고 운동 보조가 아닌 의학적으로도 활용된다면 충분히 많은 도움을 줄 수 있을 것 같다는 생각이 들었다.
Generation Model에 관한 최근 트랜드
과거부터 GAN, DCGAN, PG-GAN, StyleGan, StyleGANv2 등 다양한 생성 모델이 생성되었다. 최근에는 Diffusion이라는 모델을 이용해서 StyleGAN보다 더욱 고화질의 리얼한 이미지를 생성하고 있다. 대표적으로는 DALL-E, Imagen, Parti가 있다.
text가 주어지면 존재하지 않은 데이터를 AI가 생성해주는 것을 확인할 수 있다.
ai-workout-assistant 모델을 통해서 다양한 분야에 활용을 해보는 것은 어떨까?
Reference
- https://danbi-ncsoft.github.io/works/2021/10/01/Generator.html
- https://wikidocs.net/151937
- https://dacon.io/codeshare/5499
- https://github.com/reevald/ai-workout-assistant?linkId=8710070
LLM을 이해하기 위한 ‘Must-Read’ 같이 읽어요 😀 (1)
에디터 | 정시은
지난주는 LLM(large language model)에 대해 알아보았는데요.
이제부터 language model을 이해하기 위해 조금 더 깊게 들어가보도록 하겠습니다.

제가 소개해드리고 싶은 논문은 DeepMind가 작년에 발표한 ‘Formal Algorithms for Transformers’ 인데요, language model을 이해하기 위한 “must-read” 라고 합니다. 이 논문은 Transformer 아키텍쳐 및 알고리즘에 대한 포괄적인 개요를 담고 있습니다. 그렇다보니 기본적인 ML 용어들과 간단한 신경망 아키텍쳐에 익숙한 독자들을 가정으로 하고 있는데요. 본격적으로 논문을 읽고 이해하기 전, 이번주에는 글에서 다루고 있는 Transformer가 무엇인지 간단히 다뤄보도록 하겠습니다.
Transformer 모델이란?
트랜스포머 모델은 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락을 학습하는 신경망입니다. Transformer는 문장 분류, 질문 응답 등 자연어처리테스크에 사용되는 BERT 모델이나, 대화형 AI, 기계 번역, 요약 등 다양한 자연어 생성문제에 사용되는 GPT, 이미지 인식 및 분류 기술에 활용되는 ViT 등 다양한 분야에서 활용되고 있습니다.
Transformer의 성능과 Attention
가장 인기있는 딥러닝 모델로 손꼽혔던 CNN과 RNN을 이제는 트렌스포머가 대체하고 있습니다. 실제로 지난 2년간 AI관련 논문의 70%에 트렌스포머가 등장했다고 합니다. 트렌스포머의 등장전까지는 라벨링된 대규모 데이터 세트로 신경망을 훈련했다고 하는데요, 이런 데이터 세트들은 구축에 많은 시간과 비용이 소모됩니다. 트렌스포머는 요소들 간의 패턴을 수학적으로 찾아내기 때문에 이 과정이 필요없습니다. 이에 더해 트랜스포머가 사용하는 연산은 병렬 프로세싱에 적합하기 때문에 모델의 실행속도 또한 빨라집니다.
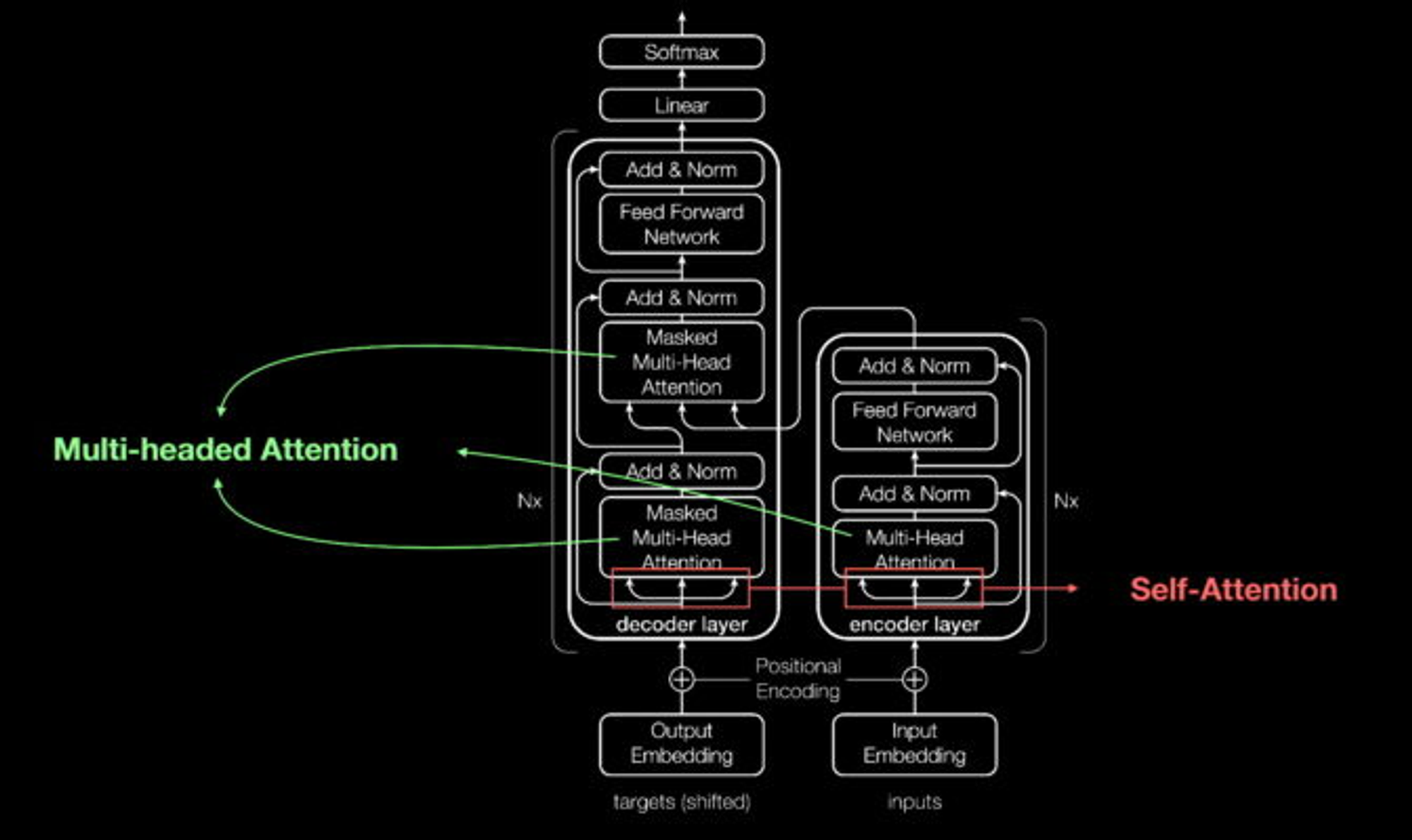
트랜스포머는 네트워크에 송수신되는 데이터 요소에 위치 인코더로 태그를 지정합니다. 이 태그를 따라 어텐션 유닛이 데이터 요소 간의 관계를 보여주는 일종의 대수 지도(algebraic map)를 계산하죠. attention query는 multi-headed attention이라 불리는 방정식들의 행렬을 계산해 대개 병렬로 실행됩니다.
오늘은 간단히 Transformer가 무엇인지에 대해서만 소개해드렸는데요, 다음시간에는 본격적으로 논문을 읽으며 Transformer의 구성요소들과 알고리즘들에 대해 자세히 뜯어보는 시간을 갖도록 하겠습니다!
CLIP - 검색엔진을 통해 수집한 데이터셋
에디터 | 송지빈
이번 포스트에서는 이미지와 텍스트의 관계를 학습하는 CLIP 논문에 대해 소개해드리려고 합니다. 2021년 1월에 공개된 오래된 논문이지만 멀티모달을 공부하는 사람들에게 도움이 되는 연구라고 생각해서 소개드립니다.
현대 컴퓨터 비전 학습 시스템은 정답 달린 형태인 레이블된 데이터셋으로 훈련합니다. 그렇기에 모든 시각적인 이미지에 대해서 레이블을 달아야하는 일반성과 편리성에 한계가 존재합니다.
이를 해결하기 위해서, CLIP 논문에서는 두 가지 방법을 제시하였습니다.
- 인터넷에 존재하는 4억 쌍의 이미지 텍스트 쌍을 크롤링하여 데이터를 확보하는 방법을 제시했습니다.
- Contrastive Learning 방식을 적용해서 Image-Text 관계를 학습하는 모델을 제시하였습니다.
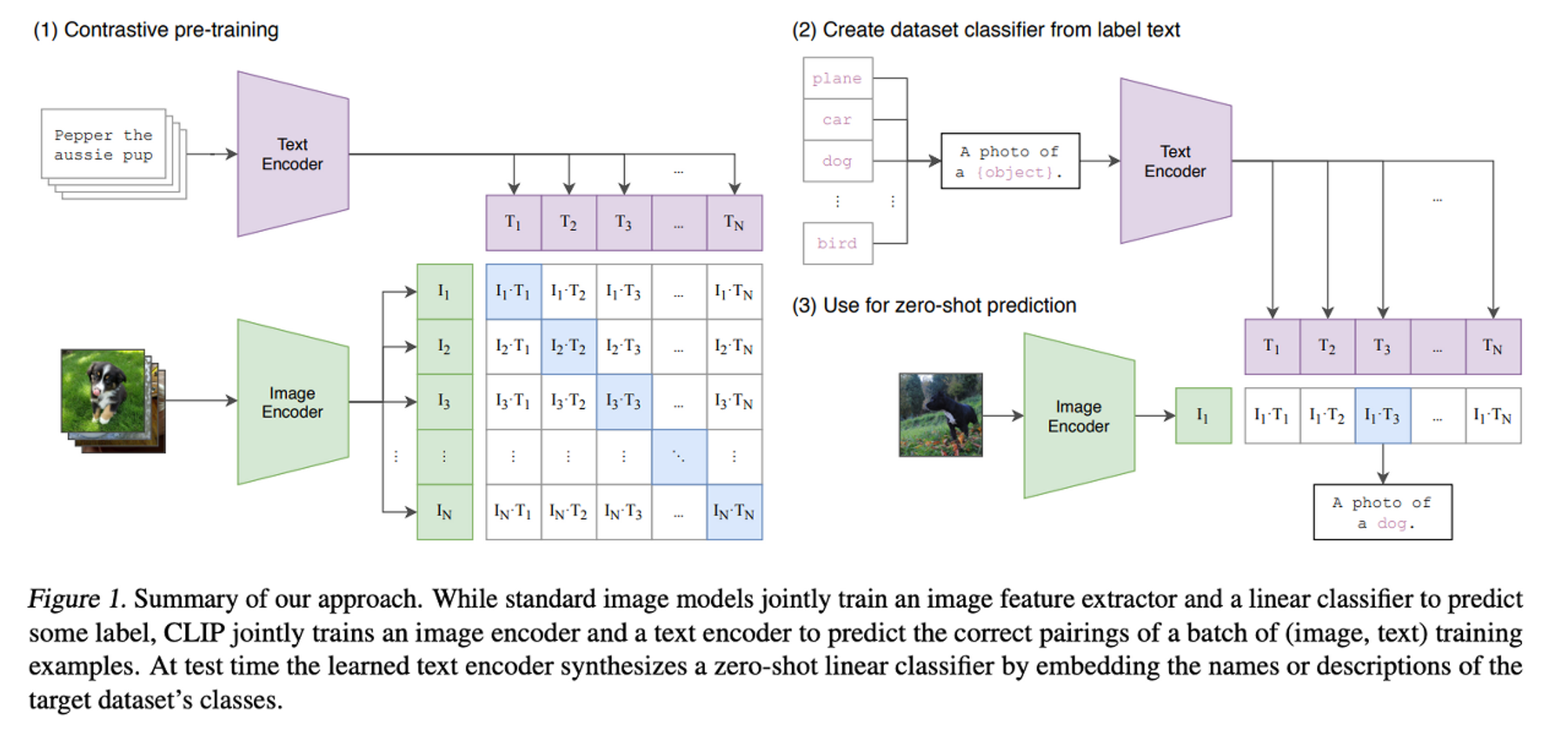
CLIP의 접근 방식
1. 데이터셋 with 자연어 Supervision
CLIP에서는 ‘Cat’, ‘Dog’, ‘Lizard’등과 같이 명사형 정답 레이블이 아니라, “pepper the aussie pup”와 같이 자연어 형식을 정답 레이블로 사용하였습니다.
이러한 자연어 Supervision 방식은 2가지 장점이 있습니다.
첫 번째로는 인터넷에 존재하는 대량의 텍스트 데이터를 이용하기 때문에 각 데이터에 정답 레이블을 직접 달 필요가 없습니다. CLIP 논문에서 다음과 같은 방법으로 인터넷 쌍에서 텍스트를 입력한 후, 이미지를 모으는 방식으로 4억 쌍의 이미지 텍스트 쌍을 크롤링하여 수집하였습니다.
두 번째로는 단지 이미지가 나타내는 표현, 특징을 학습하는 것이 아니라, 이미지의 표현과 언어를 연관지어 학습하기 때문에, 모델이 학습 과정에서 배우지 않은 작업을 수행할 수 있는 zero shot transfer가 가능합니다.
2. 학습 방법 : Contrastive Pre-Training
CLIP에서 이미지-텍스트의 관계를 학습하기 위해 Contrastive pre-training 방식을 사용하였습니다.
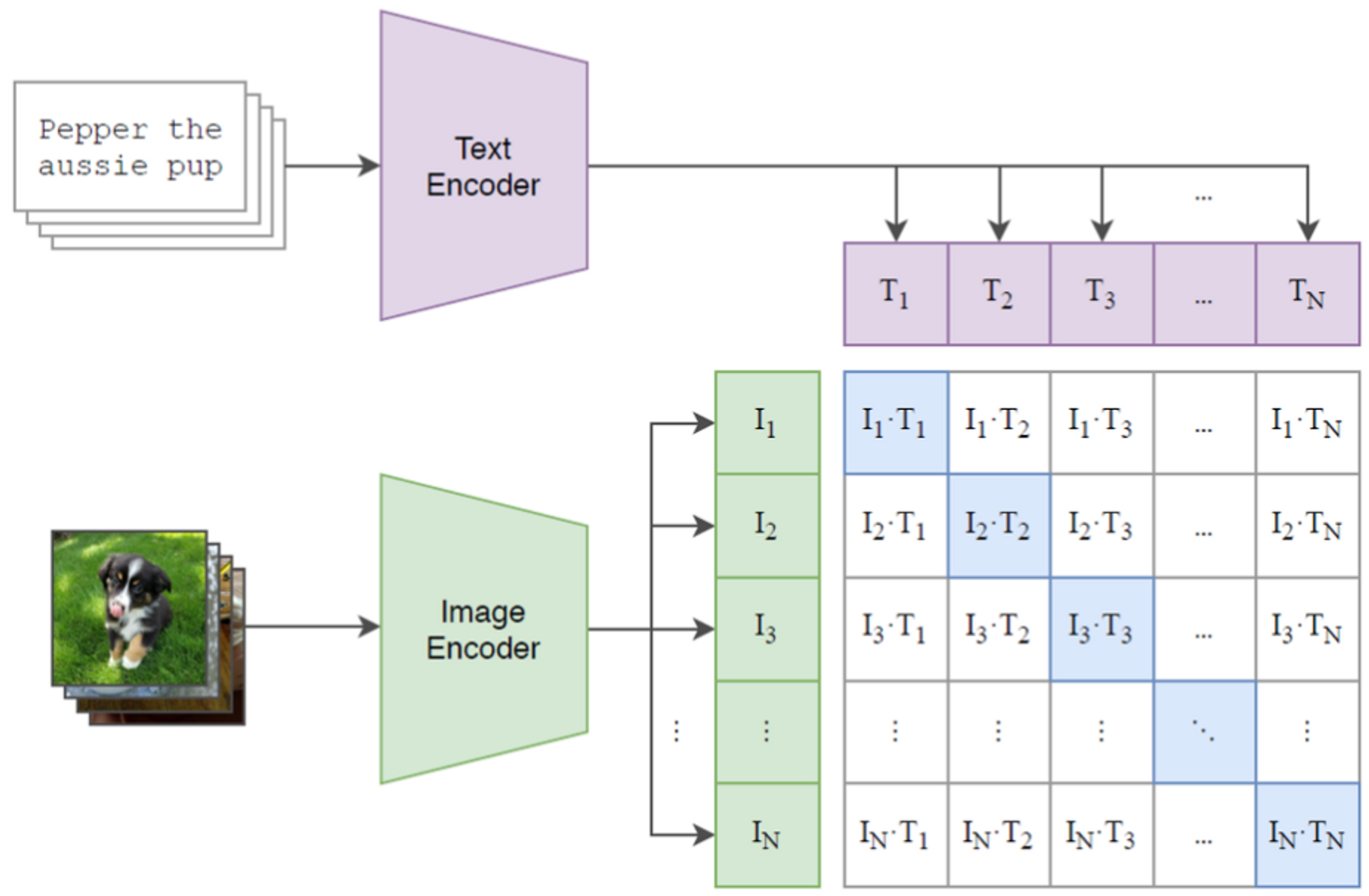
N쌍의 이미지-텍스트 데이터가 있다고 해봅시다. 저희가 얻고자하는 목표는 이미지와 텍스트를 나타내는 NxN 행렬 중에 이미지와 텍스트의 적합한 쌍을 예측하는 것입니다.
우선 NxN 행렬을 얻기 위해 멀티모달 임베딩 공간을 학습해야합니다. N개의 이미지를 Image Encoder에 통과시켜 각각 하나의 벡터 I로 만들어, 총 N개의 벡터(I1, I2, …, In)를 만들고, 각 이미지를 설명하는 텍스트는 Text Encoder에 통과시켜 각 하나의 벡터(T)로 만들어, 총 N개의 벡터(T1, T2, …, Tn)를 만듭니다.
그 다음 두 벡터를 내적하여 NxN의 행렬을 얻고, NxN 행렬에서 정답 쌍(대각 원소)의 코사인 유사도를 최대로 만들고, 오답 쌍(대각 원소를 제외한 모든 원소)의 코사인 유사도는 최소로 만드는 방식으로 학습합니다. 이때 Symmetric Cross Entropy Loss를 사용하는데 궁금하신 분들은 찾아보시면 좋을 것 같습니다.
결과적으로 코사인 유사도가 최대로 만들어지는 부분은 N개, 최소로 만들어지는 부분은 N2−N개 입니다.
결과 : Zero-Shot 성능
위의 방식을 적용하여 이미지와 텍스트의 관계를 학습한 결과에 대해 알아보겠습니다.
앞서 CLIP에서 Contrastive pre-training하여 이미지와 텍스트의 관계를 학습하였습니다. 이미지와 텍스트를 벡터로 변환한 후 이미지 벡터와 텍스트 벡터 간의 유사도를 계산하여 유사도가 커지는 방향으로 학습하였습니다.
이 모델은 Zero-Shot 이미지, 즉 학습에 참여하지 않았던 이미지를 예측할 때에 좋은 성능을 내었습니다.
Zero-Shot 이미지 예측을 할 때 예측하고자하는 이미지를 인코딩하여 벡터로 만들고, 학습에 사용되었던 분류하고자 하는 object들을 자연어 형식 “a photo of a {object}” 과 유사한 형식으로 텍스트를 만듭니다. 이 텍스트들을 각각 인코더하여 벡터로 만듭니다. 그 다음 텍스트 벡터와 이미지 벡터의 유사도를 구하여 가장 유사도가 큰 값을 갖는 텍스트를 찾을 수 있습니다.
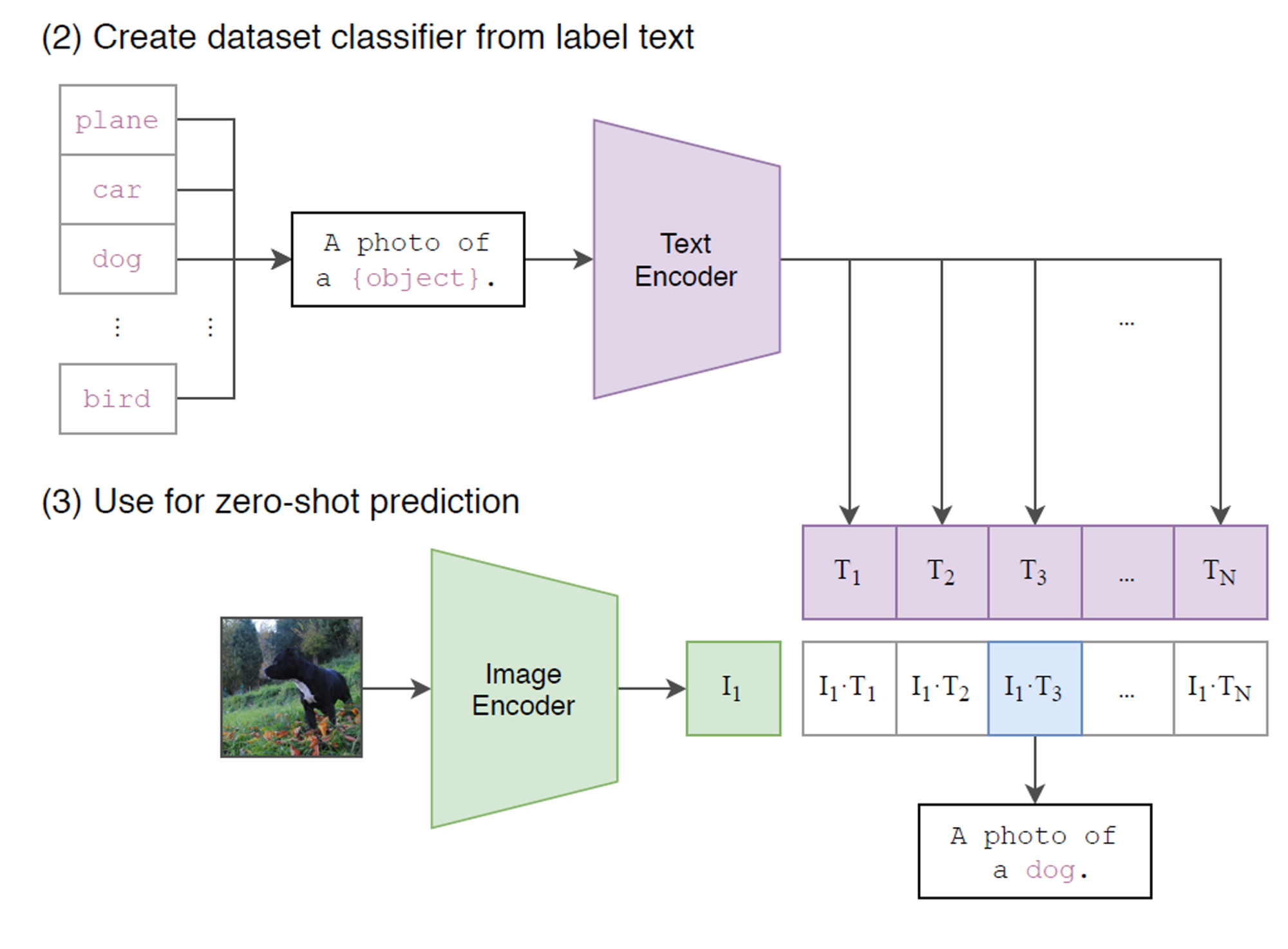
자연어 형식으로 텍스트를 만드는 이유는 object를 설명하는 자연어 형식이 object만 있는 입력값보다 더 좋은 성능이 나왔기 때문입니다.
결론
CLIP은 자연어와 이미지쌍을 학습하여 자연어로 시각적 개념을 설명할 수 있도록 하였습니다. 따라서 새로운 데이터에 대한 예측(zero-shot transfer)이 가능합니다.
또한 하나의 Input과 하나의 Output이 아닌 두 개의 Input이라는 점과 두 개의 Input이 정답 쌍에 대해 유사도를 증가시켜 학습한다는 점에서 참신한 방식이라고 생각합니다.
CLIP 이외에도 멀티모달에 다양한 방식이 있기에 다음 포스트에서는 또 다른 멀티모달 방식에 대해 다룰 예정입니다. 읽어주셔서 감사합니다.
Reference
- https://github.com/openai/CLIP
- Learning Transferable Visual Models From Natural Language Supervision
- CLIP: Connecting text and images
인간은 Backpropagation을 하지 않는다💥
Forward-Forward Algorithm
에디터 | 조유림
'Backpropagation(오차 역전파)', 이 단어는 인공지능을 공부해본 사람이라면 안 들어볼 수 없는 단어입니다. 간단히 말하면 출력으로 부터 역전파를 통해 가중치를 조정하는 것인데요. 이 오차역전파의 등장으로 딥러닝이 많은 발전을 할 수 있었습니다. 그런데 지난 1월, 오차역전파를 제안한 제프리 힌튼(Geoferry Hinton)이 흥미로운 논문을 게재했습니다. 제목은 'The Forward-Forward Algorithm: Some Preliminary Investigations', 단독 저자로 글을 작성하였습니다.
논문 제목 그대로 'Preliminary Investigations'이기 때문에, 오차역전파를 대체할 새로운 알고리즘의 등장! 보다는 '이런 식으로 생각할 수도 있구나, 이런 알고리즘을 적용해 볼 수 있겠구나.'라는 식으로 생각해보시면 좋을 것 같아요. 이번 포스트에서는 간단하게 FF Algorithm에 대해 알아보도록 하겠습니다.
1. What is wrong with backpropagation
해당 논문에서는 오차역전파의 몇 가지 부분을 지적합니다. 첫 번째로 우리의 뇌가 학습하는 데에 오차역전파를 사용하지 않고, 일종의 루프를 형성하여 신경 활동을 하므로, 오차역전파를 신뢰할 수 없다고 말합니다. 두 번째로는, 시계열 데이터를 다루려면 time-out을 취하지 않고, 다른 stage를 통해 감각 데이터 파이프 라인을 사용해 신속하게 학습할 수 있는 절차가 필요한데, 오차역전파는 이를 충족하지 못한다고 지적합니다. 마지막 세 번째로는 오차역전파가 순방향 패스(forward pass)에서 수행되는 계산에 대한 완벽한 지식이 있어야만 올바른 도함수를 도출해 낼 수 있다고 이야기 했습니다.
이러한 단점을 극복하기 위해 backward pass를 forward pass로 대체하고자 하였는데, 이는 인간의 뇌가 학습하는 과정을 본따기 위한 노력이고, 성능이 탁월하게 좋지는 않지만 인간이 실제로 학습하는 과정과 유사할 수 있도록 구성했다는 데에 의의를 둔다고 할 수 있습니다.
2. The Forward-Forward Algorithm
그렇다면 FF Algorithm은 어떻게 구성되어 있을까요?
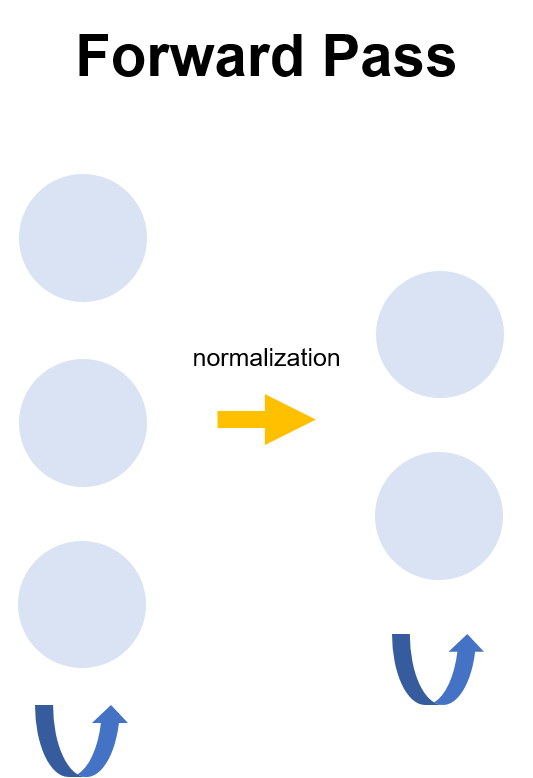
FF Algorithm은 오차역전파의 forward pass와 backward pass를 2개의 forward pass로 대체하였습니다. 두 forward pass는 goodness를 가집니다. 논문에서는 positive, negative datset을 형성하여 positive pass의 goodness를 증가시키고, negative pass의 goodness를 감소시키는 방향으로 가중지를 조정하는 방법을 택하였습니다.
2.1 Learning multiple layers of representation with a simple layer-wise goodness function
앞서 positive data와 negative data로 나뉜다고 하였는데요. positive pass의 goodness를 증가시키기 위해 positive data는 hidden units의 합이 높고, 반대로 negative pass의 goodness를 감소시키기 위해 negative data의 합은 낮아지게 됩니다. 그렇다면 첫 번째 은닉층의 출력 값이 두 번째 은닉층의 입력으로 사용된다면, 모델은 다른 것들은 무시한 채 '벡터의 길이'만으로 positive/negative를 결정짓게 됩니다. 따라서 이를 해결하기 위해 FF Algorithm은 벡터의 길이를 정규화(normalization)하는 방식을 채택하였다고 합니다.
결론
오차역전파를 능가하는 성능을 보여주지는 못했다는 점은 다소 아쉬울 수도 있습니다. 그러나 AI가 '인간의 지능을 모방하는 것'이라면 성능 자체로만 모방을 평가할 것이 아니라, 학습하고 사고하는 과정 역시 인간과 닮아야 하는 것이 아닐까?라는 질문을 던져주는 데에 의미가 있는 것 같습니다. 오차역전파를 지적하며 그와 상반되는 알고리즘을 제시하는 사람이 다른 누구도 아닌 오차역전파를 제시한 연구자 그 본인이라는 점에서도 신선하게 다가올법한 것 같습니다.