5월 3주차 GDSC Sookmyung Weekly AI Trend

역시 Google은 Google?
Google이 공개한 혁신적인 변화 소개
에디터 | 손수경
이번 주 Google I/O가 개최되었다. Google I/O란 구글에서 개최하는 개발자 컨퍼런스인데, I는 숫자 1을 의미하고 O은 숫자 0을 의미한다. 2023 Google I/O에서는 다양한 생성 모델을 통한 발전 사항에 대한 주제가 많았다. 그 중 주요 내용은 다음과 같다.
1. Google Photos - Magic Eraser
생성 모델을 통해서 아이의 위치를 바꾸더라도 어색하지 않게 이미지를 생성해준다.
2. PaLM 2
구글의 새로운 언어 모델(LLM)인 PaLM 2는 구글의 업데이트 된 Bard의 채팅 도구에 도움을 줄 것이라고 했다. 또한 OpenAI의 ChatGPT에 대한 경쟁자이며, 대부분의 AI 기능의 기초 모델로 기능할 것이라고 했다. PaLM 2 + Security Knowledge를 통해서 Sec-PaLM 2으로 Fine-Tuning 할 수 있고, PaLM 2 + Medical Knowledge를 통해서 Med-PaLM 2으로 Fine-Tuning 할 수 있다. 이번 PaLM 2는 코드 쓰기 및 디버깅을 위한 향상된 지원도 제공한다고 한다.
3. Bard
Bard에게 이미지를 입력을 하게 되면 재미있는 캡션을 작성할 수 있도록 요청할 수 있다. 또한 180개 이상의 국가 및 영토로 Bard를 개방하고 있으며 여기에 한국어도 포함된다. Bard는 PaLM 2를 기반으로 만들어졌으므로 Bard를 통해서 코딩을 할 수 있다.
사용자의 가독성을 위해서 깔끔하게 코딩을 해주는 것을 확인할 수 있다.
4. Workspace
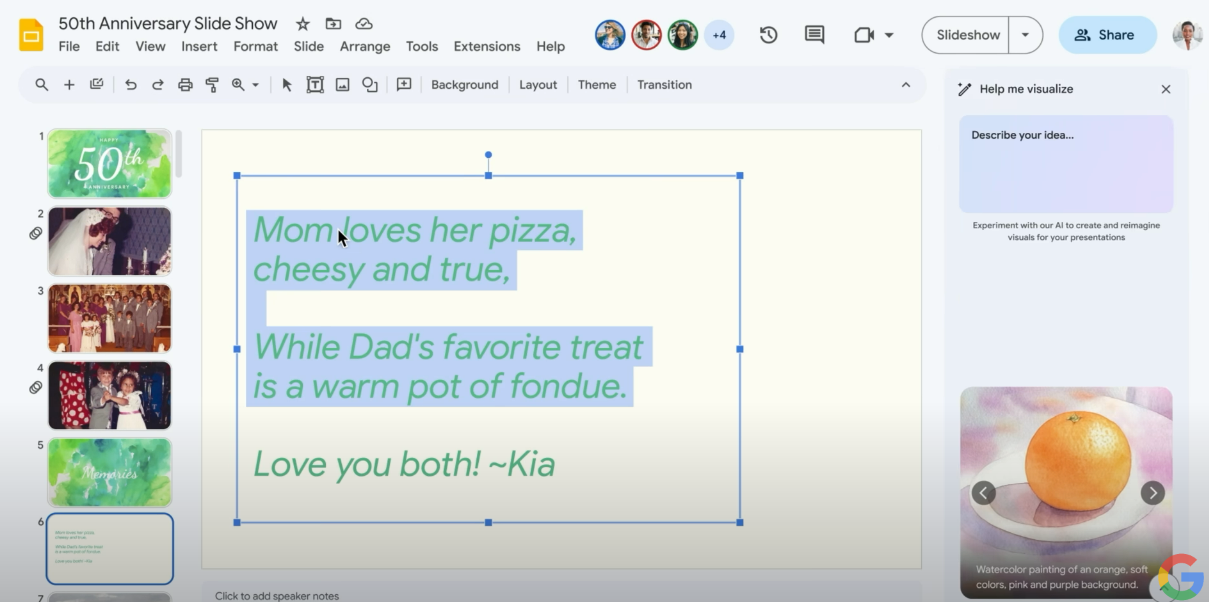
Google Slide에서는 해당 텍스트를 이미지 생성 프롬프트로 사용할 수 있는 기능이 소개되었다. 이 기능을 바탕으로 6개의 추가 생성 AI 기능을 사용해 볼 수 있다. Google Docs의 경우는 SideKick이라고 부르는 측면 패널이 출시되었다. Sidekick은 즉시 문서를 읽고 처리하며, 열린 프롬프트 대화창을 통해서 몇 가지 깔끔한 제안을 제공한다.
5. Generative AI into search
새로운 통합 검색 결과 페이지가 표시되어 단일 검색에서 더 많은 정보를 얻을 수 있다. 검색어에 대한 이미지를 빠르게 제공하고, 원하는 정보를 빠르게 제공하는 AI-powered snapshot 기능도 제공된다.
6. MusicLM
이미 text-to-image, text-to-video, text-to-animation 모델이 등장하고 있는 가운데, text-to-music 모델도 소개를 했다. 원하는 분위기를 프롬프트하면 이에 해당하는 음악으로 바꾸어준다.
그 외의 Google이 소개한 다른 기술들도 보고 싶다면 다음 링크를 통해서 확인해보면 좋을 것 같다 😄 https://www.youtube.com/watch?v=QpBTM0GO6xI&list=TLGGCy91ScdjTPYxMTA1MjAyMw
References
- https://www.youtube.com/watch?v=QpBTM0GO6xI&list=TLGGCy91ScdjTPYxMTA1MjAyMw
- https://techcrunch.com/2023/05/10/heres-everything-google-has-announced-at-i-o-so-far/
구글(Google)이 주최한
Kaggle Competiton 안내
에디터 | 조유림
안녕하세요! 오늘은 Google I/O 2023과 함께 올라온 Google의 Kaggle Competition을 안내해드리려고 합니다.
Google - American Sign Language Fingerspelling Recognition
미국 수화 손글씨 인식 모델 개발

Google - American Sign Language Fingerspelling Recognition | Kaggle
www.kaggle.com
Goal of the Competition
미국 수화(ASL) 손글씨를 감지하고, 텍스트를 번역하는 모델 개발 대회입니다. 다양한 배경과 조명 조건에서 스마트폰 셀프 카메라로 촬영된 100명 이상의 청각 장애인 수화 사용자가 생성한 300만 개 이상의 손글씨 문자로 구성된 대규모 데이터셋이 제공됩니다.
Dataset Description
- Size 189.26GB
- TensorFlow Lite 모델 형식으로 제출
- 제출 전에 모델 체크포인트를 tflite 형식으로 변환해야 함
Timeline
- May 10, 2023 - Start Date.
- August 3, 2023 - Entry Deadline. You must accept the competition rules before this date in order to compete.
- August 3, 2023 - Team Merger Deadline. This is the last day participants may join or merge teams.
- August 10, 2023 - Final Submission Deadline.
ImageBind: 6가지 감각을 결합한 멀티모달 모델
에디터 | 송지빈

안녕하세요! 이번 포스트에서는, 다양한 형태의 정보를 동시에 전체적으로 학습하여 인간의 능력에 한 걸음 더 가까이 다가갈 수 있는 접근 방식에 대해 소개해드리려고 합니다. Meta AI에서 6가지의 모달(감각)을 결합한 최초의 AI 모델인 ImageBind를 구축하고, 이를 오픈소스로 공개하고 있다는 사실 알고 계신가요? 이 모델은 텍스트, 이미지, 비디오, 오디오뿐만 아니라 깊이(3D), 열(적외선), 동작과 위치를 계산하는 관성 측정하는 센서에 대해서도 모두 함께 학습할 수 있습니다. 사진 속 물체의 소리, 3D모양, 따뜻하거나 차가운 정도, 움직이는 방식 등을 종합적으로 파악할 수 있다는 의미입니다.

ImageBind는 구체적으로 어떻게 적용할 수 있을까요? ImageBind를 사용하여 열대 우림이나 북적이는 시장의 소리를 기반으로 이미지를 생성할 수 있고, ImageBind는 3D센서와 IMU센서를 사용하기 때문에, 몰입형 가상 세계를 설계하거나 경험할 수 있는 개발의 문을 열어줍니다. 또한 사진, 비디오, 오디오 파일, 또는 문자 메시지를 검색하는 등 검색에 대해서 풍부한 방법을 제공할 수 있습니다.
이미지와 결합하여 단일 임베딩 공간 학습하기

사람은 몇 가지 예시만으로 새로운 개념을 학습할 수 있는 능력이 있습니다. 우리는 동물에 대한 설명을 읽은 후에 실제 동물을 알아볼 수 있습니다. 또한 생소한 자동차 모델의 사진을 보고 엔진 소리가 어떻게 들릴지 예상할 수 있습니다.
바로 하나의 이미지가 전체 감각 경험을 ‘결합’할 수 있기 때문입니다.
ImageBind는 최근의 대규모 비전-언어 모델을 활용하고, 비디오-오디오 이미지-깊이(3D) 데이터와 같이 이미지와 자연스러운 페어링을 사용하여 이미지와 전체 감각 경험을 결합시켰습니다.
ImageBind는 이미지 페어링 데이터만으로도 여섯 가지 모달리티를 하나로 묶을 수 있습니다. 예를 들어 오디오와 텍스트를 함께 보지 않고도 이미지 페어링 데이터로 학습했기 때문에 이 두 모달리티를 연관지을 수 있게됩니다. 즉 오디오, 텍스트 개별적인 훈련 없이도 새로운 모달리티를 이해할 수 있습니다.
멀티모달 학습의 미래

다양한 모달리티를 입력으로 넣고 다른 모달리티를 출력하는 기능을 갖춘 ImageBind는 크리에이터에게 새로운 가능성을 보여줍니다. 바다의 일몰을 촬영한 비디오에 완벽한 오디오 클립을 추가하여 품질을 향상시키고, 시츄 강아지 이미지를 통해 유사한 강아지의 에세이나 입체 모델을 생성할 수 있습니다.
또한 메타의 Make-A-Video와 같은 모델이 카니발 비디오를 제작할 때 ImageBind는 배경 소음을 함께 제안하여 몰입감 있는 환경을 조성할 수 있습니다.

심지어 오디오를 기반으로 이미지 속 사물을 세분화하여 식별할 수도 있습니다. 예를 들어, 알람 시계와 키보트 타이핑 소리가 있는 이미지를 결합하고, 키보드 타이핑 오디오 프롬프트를 사용하여 키보드나 알람 소리를 분할하여 시계를 분할하고 둘 다 비디오 시퀀스로 애니메이션화할 수 있습니다.
현재 연구에서는 6가지 모달리티를 살펴보았지만, 터치, 음성, 후각, 뇌 fMRI 신호 등 가능한 많은 감각을 연결하는 새로운 모달리티를 도입하면 더욱 풍부한 인간 중심 AI 모델을 구현할 수 있을 것으로 기대됩니다.
References
- ImageBind: Holistic AI learning across six modalities
- https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
BEHRT: 질병예측모델
에디터 | 정시은
오늘날 의학이 발전하고 의료에 대한 관심이 증가하고 있음에도 불구하고 대부분의 진단은 환자들이 눈에 띄는 질병의 징후를 보이기 시작하면 일어납니다. 이 연구는 301개의 조건의 가능성을 동시에 예측할 수 있는 전자 건강 기록(EHR)을 위한 심층 신경 시퀀스 변환 모델인 BEHRT 를 소개합니다. 약 160만명의 개인 데이터에 대해 훈련하고 평가했을때, BEHRT는 기존의 모델 EHR 에 비해 8.0~13.2%의 놀라운 향상을 보여줍니다. 확장성과 우수한 정확성 외에도, BEHRT는 예측에 대한 개인화된 해석을 가능하게 합니다.
Methods
Data
- 적어도 5번의 방문이 있는 사람들만 EHR에 보관( 160만명의 환자)
- 301개의 진단코드와 나이 학습을 위한 시계열 데이터 사용
Architecture

- 환자의 과거 EHR을 사용해 다중레이블분류문제로 향후 진단을 예측
- 진단을 단어로, 방문을 문장으로, 전체 의료 이력을 문서로 묘사
- feed forward neural networks: 시퀀스가 아닌 병렬로 데이터 학습
- embedding : 질병,위치(position), 나이, 방문세그멘트(segment A,B)
Pre-training BEHRT using masked language model (MLM)
- 질병, 연령, 세그먼트 임베딩을 무작위로 초기화
- 질병 단어의 86.5% 변경하지않고, 단어의 12%를 마스크로 대체, 나머지 1.5%의 단어는 무작위로 선택된 질병 단어로 대체
- 모델이 병의 진행에 대한 전반적인 학습을 했는지 검증하기 위해 1) 다음방문에서의 진단, 2) 다음 6개월 내의 진단, 3) 다음 12개월내의 진단을 예측하는 downstream task를 수행
Results
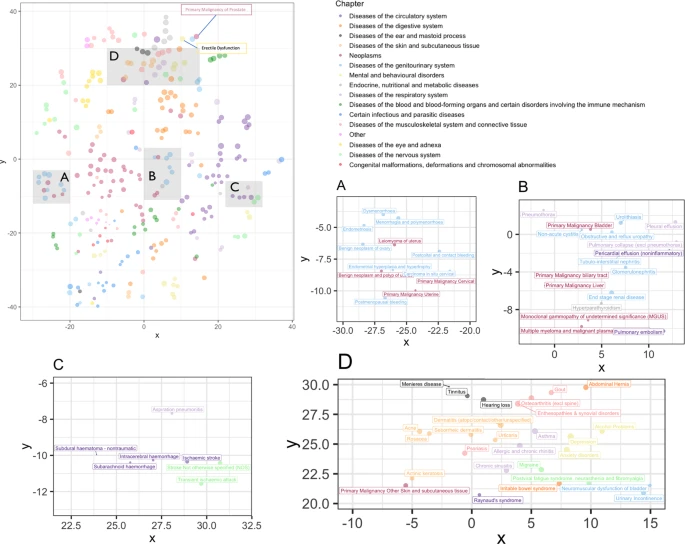
BEHRT가 질병의 잠재적 특성을 이해하는 강력한 능력을 가지고 있음을 알 수 있었습니다.

또한, BEHRT가 지닌 self-attention mechanism은 이벤트간의 관계를 찾을 수 있는 능력이 있는데, 질병사이의 비방향성 관계(둘중 하나가 하나를 유발하는 것이 아니라 서로의 대응관계)를 포착하는 것을 알 수 있습니다.
본논문에서는, 개인화된 해석이 가능한 BEHRT라는 모델을 소개합니다. BEHRT는 대규모 데이터 세트에서 사전훈련되며, 광범위한 다운스트림 task에서 놀라운 성능을 발휘합니다. 연구결과, BEHRT는 300개 이상의 질병 범위를 예측하는데 있어 EHR 모델을 8%이상 능가했습니다. BEHRT은 질병,나이, 세그먼트, 위치를 사용하는 모델을 사용합니다. 이러한 혼합을 통해 모델은 질병이 어떻게 공존하는지 보여줄 뿐만 아니라, 과거의 특정 질병이 향후 다른 질병의 위험에 미치는 영향도 보여줍니다. . 즉, “ 이 환자가 어린 나이에 질병 A와 B를 앓았는데, 갑자기 방문 빈도가 증가하고 새로운 진단 C가 나타났다. 이 모든 것과 환자의 나이를 포함하여 질병 D가 다음에 발생할 가능성이 높아진다” 와 같은 예측을 할 수 있습니다.
References