학습 링크 :
https://www.edwith.org/ai215/joinLectures/86246
딥러닝 1단계: 신경망과 딥러닝 강좌소개 : edwith
- Andrew Ng
www.edwith.org
1. 딥러닝 소개
1) 신경망(Neural Network : NN): 충분한 훈련 데이터 셋이 주어졌을 때, 신경망은 X에서 y로 정확하게 매핑되는 활성화 함수를 알아내는 데 매우 뛰어남
2) 지도학습(Supervised Learning)
- 입력 X에 대한 결과 값 y가 라벨링되어 있는(정답이 있는) 데이터를 학습시키는 방법
- 예시:
- Standard NN
- Convolution NN(images)
- Recurrent NN(audio)
3) 데이터
- 구조화 데이터(Structured Data): 모든 피쳐들이 각각에 잘 정의된 의미를 가짐
- 비구조화 데이터(Unstructured Data): Audios, Images, Text 등 각 피쳐들이 독립적인 단어나 픽셀이다
- 사람들은 구조화 데이터해 비해 비구조화 데이터를 더 잘 해석할 수 있도록 진화되어왔다
- NN의 도움으로 최근 몇 년간 컴퓨터 또한 그 전에 비해 비구조화 데이터를 잘 해석할 수 있게 되었다.
4) 딥러닝이 뜨는 이유
- 스케일의 증가
- 데이터의 양이 폭발적으로 증가함에 따라 그만큼 성능 향상의 스케일이 커짐
- 전통적인 학습 알고리즘(SVM, LR 등)은 증가하는 데이터에 대하여 학습률(정답률)에 한계가 있음
- NN의 경우 더 많은(라벨링된) 데이터가 입력될수록, 성능 또한 점점 더 좋아진다(신경망의 크기 또한 커야한다)
- 데이터의 양이 폭발적으로 증가함에 따라 그만큼 성능 향상의 스케일이 커짐
- 컴퓨팅 능력의 향상
- 컴퓨팅 능력은 점점 발전하고 있다(속도, 데이터의 용량 등)
- 알고리즘 성능의 향상
- 활성화 함수를 Sigmoid에서 RELU로 변경함에 따라 Gradient Descent의 속도가 상승하였다
- Sigmoid: 증분이 0에 가까워짐에 따라 훈련 속도가 느려짐
- RELU(Rectified Linear Unit): 모든 입력에 대해서 증분이 1이므로 0에 가까워지지 않아(부분적으로는 가능) 훈련 속도가 느려지지 않는다
- 2와 3에 의하여 훈련 시간이 급격하게 감소하였고, 더 시간-효율적으로 좋은 성과를 내는 신경망을 찾는 것이 용이해졌다.
- 활성화 함수를 Sigmoid에서 RELU로 변경함에 따라 Gradient Descent의 속도가 상승하였다
2. 신경망과 로지스틱회귀
1) 이진 분류(Binary Classification)
- 이미지
- 픽셀과 3원색으로 이루어져있음
- 0, 1(꺼짐과 켜짐)
- Sigmoid 함수를 활성화 함수로 이용함(음의 무한대로 갈수록 0, 양의 무한대로 갈수록 1)
2) 로지스틱 회귀(LR)의 비용 함수
- 손실(에러) 함수: 실제 y에 비해 예측된 y(y hat)가 얼마나 잘 예측되었는지
- Gradient Descent에서는 잘 work하지 않는다
- 비용 함수: 훈련 예시에서 W와 b가 얼마나 잘 하고 있는지
3) Gradient Descent
- W와 b 파라미터를 학습시킨다
- 어떤 W와 b가 가장 J(W, b)를 작게 만들지를 찾는다
3. 파이썬과 벡터화
1) 벡터화
- 일련의 수(Series)를 단일행 벡터로 만드는 것
-
z = np.dot(w.T, x)+b
2) 신경망 프로그래밍 가이드라인
- 절대 for 반복문을 사용하지 말 것
- 아주 큰 데이터셋에 대하여 학습을 지연시킴(벡터화 해야함)
3) 파이썬에서 브로드캐스팅
- 브로드캐스팅(Broadcasting): 차원이 맞지 않는 벡터들의 차원을 맞춰주는 것
- 예시
- [ [1], [2], [3], [4]] + 100 = [[101], [102], [103], [104]]
- [[1, 2, 3], [4, 5, 6]] + [100, 200, 300] = [[101, 202, 303], [104, 205, 306]]
- [[1, 2, 3], [4, 5, 6]]+[[100], [200]] = [[101, 102, 103], [204, 205, 206]]
4) 파이썬/넘파이 벡터
- 쓰지 말 것
# rank가 1인 array
a=np.random.randn(5)- 대신 사용할 것
# a.shape=(5, 1)
a=np.random.randn(5,1)
# a.shape=(1, 5)
a=np.random.randn(1,5)
4. 얕은 신경망 네트워크
1) 2 layer NN

2) NN의 구성
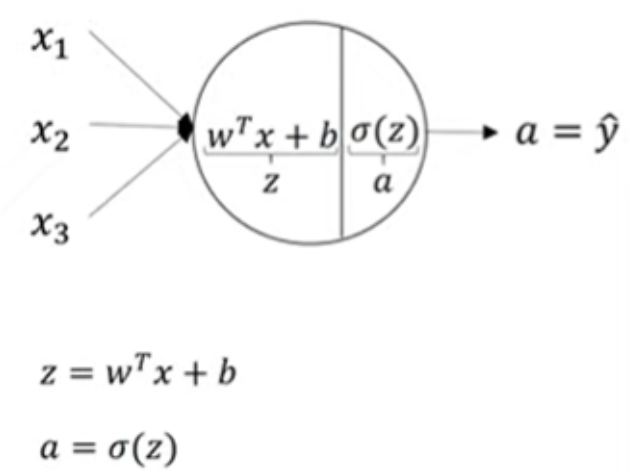
3) 활성화 함수
- Sigmoid (0, 1)

- Tanh (-1, 1)

-
- 대부분의 경우 Sigmoid보다 성능이 좋음
- (-1, 1)의 범위를 갖고 있어 평균이 0에 가까움 : 데이터를 중앙화(centerize)할 때 사용함
- 만약 출력 레이어 값이 0 또는 1(이진 분류)라면 Sigmoid가 더 나음
- ReLU

-
- 디폴트 선택으로 각광받고 있음
- 기울기가 0과 크게 차이가 있으므로(1) 학습 속도가 매우 빠름
- z가 0일 때 증분(기울기)가 0임 --> leaky ReLU가 대안으로 나옴
- leaky ReLU

-
- 0.01은 충분히 변경 가능한 숫자(지만 아무도 시도하지 않음)
-

- 왜 비선형 활성화 함수를 쓰는가?
- 선형함수를 사용하면 신경망의 깊이에 관계 없이 항상 선형적인 값이 나옴(y=x의 합성함수를 생각하면 됨)
- layer를 쌓는 이점을 취할 수 없음
4) 활성화 함수의 미분 값

5) 랜덤 초기화
- 만약 신경망이 0으로 초기화되어 있다면 Gradient Descent가 먹히지 않음
- 모든 히든 레이어가 같은 함수를 계산하게 됨
- -> 다음 유닛에 같은 결과를 줌
- -> 유닛을 가지는 의미가 없음
- 대신, W를 랜덤으로 초기화: W를 초기화했으므로 b는 그와 같은 문제를 갖지 않음
w_i = np.random.randn((2, 2))*0.01
b_i = np.zero((2, 1))- 왜 0.01?
- 작은 값이 필요함
- W값이 너무 클 경우, 훈련의 시작을 아주 큰 z로 할 가능성이 높음
- -> 값들이 너무 크거나 너무 작아짐
- -> Tanh나 Sigmoid가 과장될 가능성이 높음
- -> Gradient Descent를 아주 느리게 만듦 -> 훈련도 느려짐
- Tanh나 Sigmoid를 사용하지 않을 경우 큰 문제는 아니지만, 이진 분류를 하거나 두 함수 중 하나를 활성화 함수로 사용한다면 파라미터의 크기가 커선 안 됨
5. 심층 신경망 네트워크
1) 심층
- 크다?: 은닉층이 크거나 개수가 많다
- 심층의 직관적인 의미: Drill down하는 것
- 작고 단순한 것에서 크고 복잡한 것까지(CNN)
- 이미지의 경우 단순 경계를 찾는 층부터 사물을 인식하는 층까지
- Circuit 이론
- 비공식적으로, 얕은 네트워크에서 계산하는 데 기하급수적으로 더 많은 은닉 유닛이 필요한 작은 L-Layer 심층 신경망으로 계산할 수 있는 기능이 있다.
- 다중 은닉층 사용 시 네트워크의 깊이는 O(log n)이며, 많은 논리 게이트가 필요하지 않다
- 다중 은닉층을 사용하지 않ㅇ는다면 기하급수적으로 많은 은닉층과 논리게이트가 필요하다(bit의 수만큼)
2) 파라미터와 하이퍼 파라미터
- 파라미터: W1, b1, W2, b2 등등
- 하이퍼 파라미터: 궁극적인 파라미터(위의)를 조정할 수 있는 파라미터(변수)들
- 학습률 alpha
- 반복회수
- 은닉 레이어 수 l
- 은닉 유닛 n1, n2, ...
- 활성화 함수의 종류
- 딥러닝을 활용한다는 것
- 체험적이고 경험적인 과정(Serendipity)
- 시도하고 바꿔보고 다시 시도할 것(비용 함수를 보여 하이퍼 파라미터 조정해보기)
- 일정 범위의 값들로 하이퍼 파라미터를 조정해보자
- 현재 가장 최선의 하이퍼 파라미터 값들 일지라도, 몇년 후 인프라 구조나 CPU, GPU의 종류에 따라 그 값이 바뀔 수 있음
3) 뇌와 신경망
- 쉽게 이해하고, 보도하고, 마케팅하기 위해서 사용되는 것
- 입력과 출력이라는 유사한 로직이 있음
- 특히 CV(Computer Vision)의 경우 뇌로부터 많은 영향을 받음
'Group Study (2021-2022) > Machine Learning (GAN)' 카테고리의 다른 글
| [Machine Learning] 6주차 스터디-조건부 GAN (0) | 2021.11.22 |
|---|---|
| [Machine Learning] 5주차 스터디-합성곱 GAN (0) | 2021.11.12 |
| [Machine Learning] 3주차 스터디 - 파이토치와 신경망 기초 (0) | 2021.11.08 |
| [Machine Learning] 4주차 스터디-튼튼한 GAN 만들기 (0) | 2021.10.31 |
| [Machine Learning] 2주차 스터디 - 심층 신경망 성능 향상 시키기, 합성곱 신경망 네트워크(CNN) (0) | 2021.10.12 |