RNN[Recurrent Neural Network]
RNN 등장 배경
이전의 Neural network는 하나의 x 입력에 대한 y출력의 간단한 형태였기 때문에 sequence data를 처리하기 어려웠음!
RNN이 등장하면서 series data, 즉 이전 데이터가 다음 데이터 연산에 영향을 미치는 Sequence data에 유리해 짐.

* x 입력이 있을 때 RNN이라는 연산을 통해서 state를 계산하고 그 state가 다시 입력이 되는 형태.
* 각각의 RNN cell에서 y값을 예측해낼 수 있음.
RNN 연산
** RNN에는 'state' 라는 개념이 존재!
새로운 state를 구할 때, 이전의 state 값이 입력으로 사용됨.

1. state를 계산
- x 입력 값, 이전의 RNN cell에서 나온 값의 h값을 입력으로 파라미터로 하여 Function을 통해 구함.
2. state를 통해서 y를 계산

* vanilla RNN : wx 에 기반 / * tanh: sigmoid함수와 유사한 형태
=> 현재상태'state' 를 기억하고 다음 연산에서 사용
** ht와 y값이 각각 몇개의 벡터를 가질 지, 즉 몇개의 hidden state를 가지게 될 지는 각각의 weight의 벡터 사이즈에 따라 달라짐.
** 전체 cell에 weight 값을 동일하게 두고 학습, 출력 함
RNN 예제
character-level language model
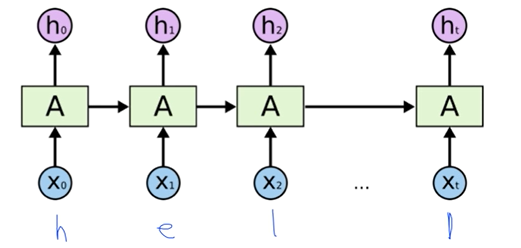
: 자연어에 character 부여
: 하나씩 입력 charcter 부여

1. 캐릭터를 벡터로 표현하여 input layer로 넣음
2. input layer에 W_xh 값을 곱해서 hidden layer 값을 만들고, W_hy를 곱해서 output layer Y를 구함.
3. softmax를 취해서 target character를 찾아냄.

one to many
: 특정이미지 입력으로 캡션을 생성하는 이미지 캡션 분야
many to many
: 문장을 입력으로 받아 문장을 출력으로 내어줌
: 문장을 입력받아 형태소로 출력하는 형태소 분석 분야
Many to One
: 자연어처리분야에서 문장/ 단어를 를 RNN 인코딩 하고, 해당 문장 단어를 classification 해줌
- sentence → word 단위로 tokenized
- sentence = word sequence 로 생각하고 문장을 워드단위로 분류 할 수 있음.
- RNN을 활용해 토큰을 읽고 마지막 토큰을 classification polarity함
- 토큰된 word는 숫자가 아니라서 RNN으로 처리 불가 → 토큰을 RNN이 처리할 수 있도록 numerical하게 만들어주는 Embedding layer가 필요함.
- RNN은 토큰을 순서대로 읽어들이고, 마지막 토큰을 읽었을 때 나온 출력값과 정답간의 loss를 구하고 이를 기반으로 back propagation 통해 RNN학습.



현재 step에서 가장 중요하게 영향을 미친 인코더의 가중치를 주는 접근법으로 디코더가 어느 입력 부분에 집중해야 하는 지 알려주게 됨.