- 1주차 목표 : 머신러닝을 위한 파이썬 정복하기
- 참고 강의 : [부스트코스] 머신러닝을 위한 파이썬
1. 1주차 핵심 내용 정리
<Numpy>
- Ndarray
: np.array 함수를 활용한 배열 생성
하나의 데이터 type만 배열에 넣을 수 있음
- Array dtype
Ndarry의 single element가 가지는 data type
각 element가 차지하는 memory의 크기가 결정됨
예) np.array([[1, 2, 3], [4.5, 5, 6]], dtype=int)
→Data type을 integer로 선언
<Pandas>
- Groupby
한 개 이상의 column을 묶을 수 있음
두 개의 column으로 groupby를 할 경우, index가 두개 생성
groupby.sum()
예) df.groupby("Team")["Points"].sum()
→ "Team"을 기준으로 "Points"를 sum
- unstack()
Group으로 묶여진 데이터를 matrix 형태로 전환해줌
- fillna()
결측값을 특정 값으로 채워줌
예) fillna(0) : 데이터 내의 결측값들을 0으로 채워줌
2. 과제 풀이
<과제#1> 백준문제14888번 (연산자 끼워넣기)
14888번: 연산자 끼워넣기
첫째 줄에 수의 개수 N(2 ≤ N ≤ 11)가 주어진다. 둘째 줄에는 A1, A2, ..., AN이 주어진다. (1 ≤ Ai ≤ 100) 셋째 줄에는 합이 N-1인 4개의 정수가 주어지는데, 차례대로 덧셈(+)의 개수, 뺄셈(-)의 개수, ��
www.acmicpc.net
- 구현원리
maxresult와 minresult를 가질 수 있는 최소와 최대 값을 설정해놓고 백트랙킹을 이용하여 모든 경우를 탐색하게 함.
함수 dfs를 만들어 처음으로 입력받은 수만큼 함수를 돌면 maxresult와 minresult를 확정시키고 함수를 종료하게 함.
- 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
def dfs(i, res, plus, minus, mul, div):
global maxresult, minresult
if i == num:
maxresult = max(res, maxresult)
minresult = min(res, minresult)
return
else:
if plus:
dfs(i+1, res+numbers[i], plus-1, minus, mul, div)
if minus:
dfs(i+1, res-numbers[i], plus, minus-1, mul, div)
if mul:
dfs(i+1, res*numbers[i], plus, minus, mul-1, div)
if div:
dfs(i+1, int(res/numbers[i]), plus, minus, mul, div-1)
num = int(input())
numbers = list(map(int, input().split()))
plus, minus, mul, div = map(int, input().split())
minresult = 100000001
maxresult = -100000001
dfs(1, numbers[0], plus, minus, mul, div)
print(maxresult)
print(minresult)
|
cs |
해설 영상 : www.edwith.org/aipython/lecture/24070/
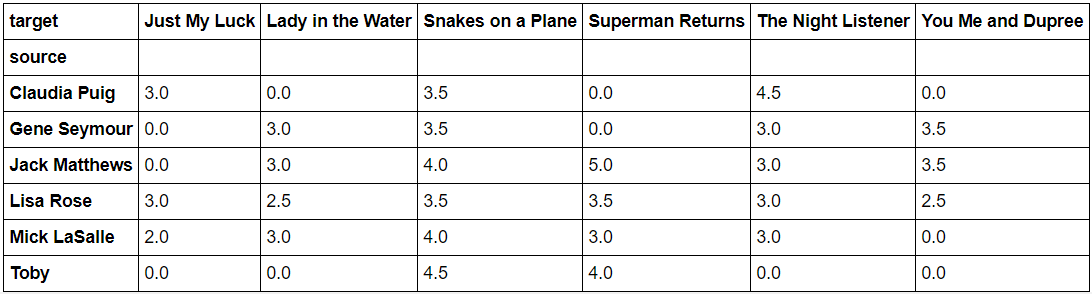
<과제#2> Pandas와 Numpy를 이용하여 Rating Matrix 만들기
- 구현원리
dtype을 사용하여 데이터의 각 element가 차지하는 memory의 크기를 float32로 설정함
pd.read_csv를 사용하여 사용할 데이터를 불러옴
groupby(['source', 'target'])['rating'].sum().unstack().fillna(0)를 사용하여 'source'와 'target'을 묶고 이 둘을 바탕으로 'rating'을 sum 해줌
fillna(0)을 사용하여 결측값들을 0으로 채우고 unstack()을 사용하여 matrix 형태로 전환함
- 코드
|
1
2
3
4
5
6
7
8
|
import pandas as pd
import numpy as np
def get_rating_matrix(filename, dtype=np.float32):
df = pd.read_csv(filename)
return df.groupby(['source', 'target'])['rating'].sum().unstack().fillna(0)
# 실행결과확인
get_rating_matrix("movie_rating.csv")
|
cs |
'Group Study (2020-2021) > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 6주차 스터디 - 이미지 처리 기본 (0) | 2020.11.20 |
|---|---|
| [Machine Learning] 5주차 스터디 - 추천 시스템 (0) | 2020.11.10 |
| [Machine Learning] 4주차 스터디 - 나이브 베이즈 분류기 (0) | 2020.11.08 |
| [Machine Learning] 3주차 스터디 - 텍스트 분석 기초 (0) | 2020.10.29 |
| [Machine Learning] 2주차 스터디 - 머신러닝 기본기 다지기 (0) | 2020.10.21 |