- 2주차 목표 : 머신러닝 기본기 다지기
- 참고 강의 : [구름EDU] 머신러닝 이론 및 파이썬 실습
✔ 머신러닝 기본 용어 정리
< overfitting & underfitting >

-
오버피팅(overfitting)이란?
=> 모델이 실제 분포보다 학습 샘플들 분포에 더 근접하게 학습되는 현상
-
언더피팅(underfitting)이란?
=> 모델이 너무 간단하기 때문에 학습 오류가 줄어들지 않는 것
-
underfitting 막는 방법 2가지
1)teach your machine with more features
2) high variance machine learning models like Decision Tree, K-NN, SVM => Low Bias High Variance -
overfitting 판단 방법
=> training data에서는 잘 예측하지만, 새로운 데이터에서는 잘 예측하지 못하면(오류 증가) overfitting 이다.
-
overfitting 막는 방법
-
정규화 : 모델의 형태를 최대한 간단하게 만드는 기법
-
Using validation data set :모델의 성능저하가 심해지면 하이퍼 파라미터 값을 수정함.
-
early stopping: validation accuracy가 더 안 올라가면 멈춘다.
-
drop out: training 과정 중 몇개의 뉴런을 쉬게함
-
< Norm >
: 벡터의 길이 혹은 크기를 측정하는 방법(함수)
- Norm 수식
- np.linalg.norm(x, ord=None, axis=None, keepdims=False)
- L1 Norm 수식
- L1_norm = np.linalg.norm(x, axis=1, ord=1)
- L2 Norm 수식
- L2_norm = np.linalg.norm(x, axis=1, ord=2)
- L2 Norm이 사용되는 machine learnign 알고리즘
- KNN, K-means알고리즘
<PCA 차원 축소>
: 많은 feature로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성
- 차원 축소의 이유
:시각화 / 노이즈 제거 / 메모리 절약 / 퍼포먼스 향상
<Confusion Matrix>
:정확도 내의 세부적인 내용을 알기 위해 사용함
=>열은 예측값, 행은 실제값


-Confusion Matrix with Normalization


< 다중 분류 모델 성능 평가 >
1) Accuracy : 정답 클래스 수 / 모든 클래스 수
2) Precision : true라고 예측한 것 중에 진짜 true인 비율
3) Recall: 실제 true인 것 중 잘 예측한 true의 비율
4) f1 Score: Precision과 Recall의 조화평균

Accuracy : TP -> 9 + 15 + 24 + 15 = 63 , Sum( TP + TN + FP + FN ) = 80
TP/Sum= 63/80= 0.78
Average Precision : (P(A) + P(B) + P(C) + P(D)) / 4 = 3.09
P(A)= 9/15, P(B)=15/20, P(C)=24/28, P(D)=15/17
Average Recall : R(A) + R(B) + R(C) + R(D) / 4
R(A)= 9/10, R(B)=15/20, R(C)=24/30, R(D)=15/20
f1 score : 2(pr)/(p+r) = 0.78
precision * recall = 0.77 * 0.8 = 0.616
precision + recall = 0.77 + 0.8 = 1.57
✔ 머신러닝 알고리즘
❄ Linear Regression
* x는 독립변수, y는 종속 변수
: 1개 이상의 독립변수 x와 y의 선형 관계를 모델링한다. 독립변수 x가 1개라면 단순 선형 회귀라고 한다.
< 단순 선형 회귀 분석(simple Linear Regression Analysis) >
=> y=Wx+b : W는 가중치, b는 편향 (적절한 W, b값을 찾는 것)
< 다중 선형 회귀 분석 (multiple Linear Regression Analysis) >
=> y=W1x1+ W2x2+.....+Wnxn+b : ex) 다수 요소를 가지고 예측을 진행할 때 y는 여전히1개
-
Cost Function : MSE(평균 제곱 오차)
: 실제값과 가설로부터 얻은 예측값의 오차를 계산하는 식을 세우고, 이 식의 값을 최소화하는 최적의 W와 b를 찾아냄
- 실제값과 예측값에 대한 오차에 대한 식: 목적 함수/비용 함수/손실 함수
- 회귀문제의 경우, 평균 제곱 오차(MSE: 오차의 제곱합에 대한 평균)가 사용됨
- y와 x 관계를 가장잘나타내는 직선그리기=모든 점들과 위치적으로 가장 가까운 직선그리기
- 오차: 실제값 y와 직선에서 예측하고 있는 H(x) 값의 차이 ←이걸 줄여 나가면서 찾아낸다
- Optimizer : Gradient Descent (경사하강법)
-
경사하강법: 접선의 기울기가 0인 곳을 향해 W의 값을 변경하는 작업을 반복
-수많은 머신/딥러닝 학습은 결국 비용함수를 최소화하는 매개변수인 W,b를 찾기 위한 작업을 수행한다. **이때 사용되는 알고리즘을 옵티마이저(최적화 알고리즘)**이라 함.
학습률 α: W의 값을 변경할 때, 얼마나 크게 변경할지를 결정
-
학습률 α가 지나치게 높은 값 ⇒ W의 값이 발산
-
학습률 α가 지나치게 낮은 값 ⇒ 학습 속도 느려짐
-
<정리>
-가설, 비용함수, 옵티마이저의 개념을 제대로 이해하자
-선형 회귀에서의 가장 적합한 옵티마이저와 비용함수는 경사 하강법과 MSE가 있음
❄Logistic Regression
< 이진분류(Binary classification) >
: 이진 분류 문제를 풀기위한 대표적인 알고리즘이 로지스틱 회귀이다.
-0과 1의 값을 확률로 해석 (선형 회귀는 적합하지 않음)
Sigmoid function (시그모이드 함수)
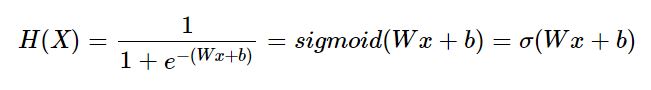
-출력값을 0과 1사이의 값으로 조정하여 반환
ex) 출력값이 0.5 이상이면 1(True), 0.5이하면 0(False)
-W= 그래프의 경사도 / b= 위아래(y축)로 그래프 이동
비용 함수 (Cost Function)

=> 옵티마이저로 경사하강법을 쓰지만, MSE는 사용하지 않아!
-가중치를 최소화하는 W값을 찾아내는 목적함수 : 크로스 엔트로피 함수(Cross Entropy)
: f는 실제값 y와 예측값 H(x) 의 오차를 나타내는 함수
- y=1→cost(H(x),y)=−log(H(x))if y=1→cost(H(x),y)=−log(H(x))
- y=0→cost(H(x),y)=−log(1−H(x)) ⇒ cost(H(x),y)=−[ylogH(x)+(1−y)log(1−H(x))]
'Group Study (2020-2021) > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 6주차 스터디 - 이미지 처리 기본 (0) | 2020.11.20 |
|---|---|
| [Machine Learning] 5주차 스터디 - 추천 시스템 (0) | 2020.11.10 |
| [Machine Learning] 4주차 스터디 - 나이브 베이즈 분류기 (0) | 2020.11.08 |
| [Machine Learning] 3주차 스터디 - 텍스트 분석 기초 (0) | 2020.10.29 |
| [Machine Learning] 1주차 스터디 - 머신러닝을 위한 파이썬 (0) | 2020.10.13 |