스탠포드대학에서 발표한 CNN 강의 영상을 듣고 자료를 정리했습니다.
| Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition https://youtu.be/vT1JzLTH4G4 |
| Lecture 2 | Image Classification https://youtu.be/OoUX-nOEjG0 |
Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition
Computer Vision이란?
컴퓨터 과학의 연구 분야 중 인간이 시각적으로 하는일들을 대행하도록 시스템을 만드는 것이다.
Vision의 역사
생물학적 Vision
빅뱅을 시작으로 생물이 진화하면서 현재 Vision은 동물의 큰 감각 체계가 되었다.
인간의 대뇌 절반 가량의 뉴런이 시각 처리에 관여할 정도로 큰 부분을 차지한다.
인공적 Vision
1600년대 카메라인 Obscura 발명을 시작으로 카메라 기술이 발전하였고,
지금까지 가장 많이 사용하는 센서중 하나이다.
Computer Vision의 역사
1. 포유류의 시각처리방식 연구(Hubel & Wiesel, 1959)
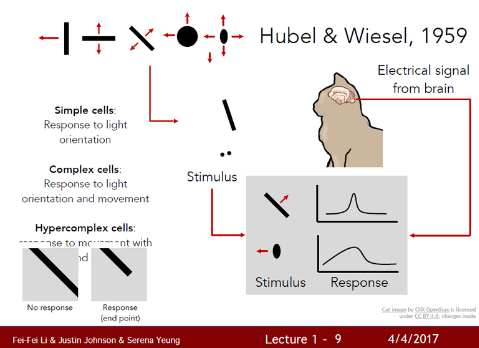
고양이의 뇌에 전기적 신호를 보내고 1차 시각 피질에 다양한 종류의 세포가 있음을 발견했다.
Simple cells
1차 시각 피질에서 가장 중요한 세포이며, 시각처리가 시작되는 곳이다.
특정한 방향으로 이동할 때 oriented edge에 반응한다.
즉, 시각 처리가 단순한 구조로 시작하여 점점 복잡해지는 것을 발견하였다.
2. Block World(Larry Roberts, 1963)

사물의 특징을 얻기 쉽도록 실제 사물을 기하학적인 모양으로 단순화하는 모형을 제시하였다.
3. The Summer Vision Project(MIT, 1966)
4. Hierachical Model(David Marr, 1970s)

우리의 눈에 인식된 이미지를 3D로 표현하기 위한 3단계 과정을 정의하였다.
5. Generalized Cylinder(1979), Pictorial Structure(1973)

모든 물체는 단순한 기하학적 구조로 이루어졌다
6. 이미지 인식을 객체 분할로 시작(1980s)

배경: 실제 세계를 단순화된 구조로 인식하기 어려움
이미지의 픽셀들을 그룹화하여 의미있는 영역으로 분할하는 방식으로 이미지 분류를 하였다.
7. Face Detection(Paul Viola, Michael Jones, 2001)

8. Shift & Object Recognition(David Lowe, 1999)

같은 객체임에도 불구하고 카메라 각도에 따라서 이미지를 다르게 인식하는 문제가 발생한다.
이에 연구 방향이 객체 분할에서 객체 인식으로 바뀌었다.
객체를 인식하기 위한 중요한 특징을 찾고 → 유사한 객체와 그러한 특징들을 맞춰보며 객체를 인식하는 방식을 사용한다.
ImageNet Project
세상 모든 이미지 분류
기계학습의 Overfitting 문제(고차원 데이터 & 훈련 세트 부족) 극복

2012년 ImageNet 국제대회 ILSVRC 개최에서 CNN(Convolutional Neural Network) 도입으로 기존 28.2%, 25%의 오류율을 16.4%로 오차율이 급격히 감소되었다.
Lecture 2 | Image Classification
Image Classification이란
컴퓨터 비전에서 가장 중요한 Task
이미지가 주어졌을 때 시스템에서 미리 label해놓은 분류된 이미지 집합 중, 어디에 속할지 컴퓨터가 판단하는 것
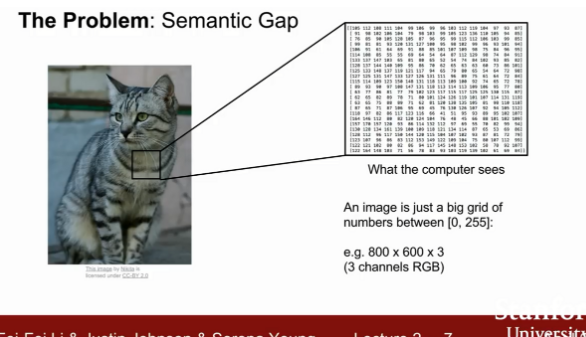
문제: Semantic Gap
카메라 각도나 밝기, 객채의 행동 혹은 가려짐 등 여러차이로 인해 이미지의 픽셀 값이 달리 읽어 사물을 다르게 인식하는데, 고양이라는 객체와 컴퓨터가 보는 픽셀의 숫자들 간에 격차가 생김
방법 1

방법2
데이터 중심 접근 방법(Data-Driven Approach)

Nearest Neighbor(NN)
입력받은 데이터를 저장한 다음 새로운 입력 데이터가 들어오면, 기존 데이터에서 비교하여 가장 유사한 데이터를 찾아내는 매우 간단한 방식
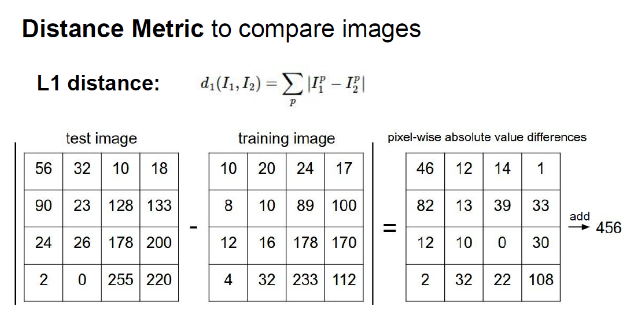
단점: 모든 사진의 픽셀값의 계산하기 때문에 예측 과정에서 소요되는 시간이 상당하다.
방법: K-Nearest Neighbors

Distance metric를 이용해서 가까운 이웃을 k개만큼 찾고, 이웃간에 투표를 하여 득표수가 많이 얻은 label로 예측하는 방법
가장 가까운 이웃이 존재하지 않으면 흰색으로 표기된다.
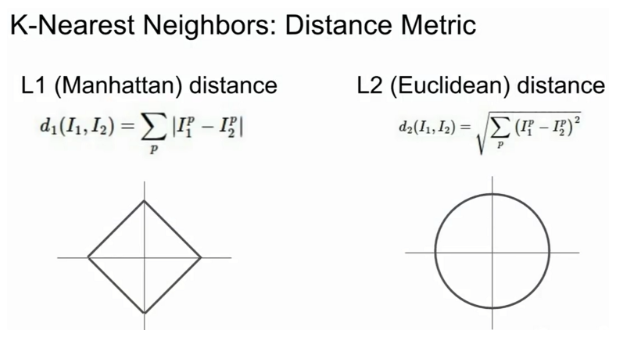
L1 Distance
마름모 형태
좌표계를 회전 시 거리값이 달라짐
L2 Distance(Euclidean Distance)
원형의 형태
좌표계를 회전해도 거리값은 좌표의 영향을 받지 않는다.
KNN이 이미지 분류에 실제로 사용되지 않는 이유
1. 너무 느림
2. L1, L2 Distance는 이미지 거리 구하는데 적합하지 않다.

Linear Classification(선형분류)
Neural Network(NN)과 Convolution Neural Network(CNN)의 기반 알고리즘으로 매우 중요하다.
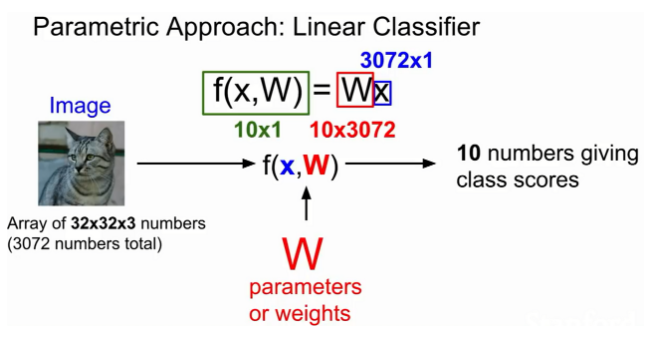
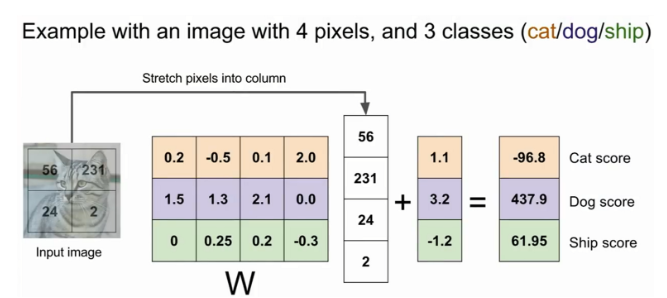
위 고양이 사진(2x2)을 예시로 입력(X)을 받으면 , 가중치 파라미터(W)와 곱하여 카테고리 score 값(f(x,w))인 10을 만든다. score값이 높을수록 고양이일 확률이 높다.
W*x 에 bias(편향값)을 더하는데, bias는 입력과는 직접적인 관계를 가지지 않으나 이미지 라벨의 불균형한 상태 보완하기 위해 사용된다.
가중치 행렬의 행벡터를 가지고 다시 이미지로 나타낼 수 있다.

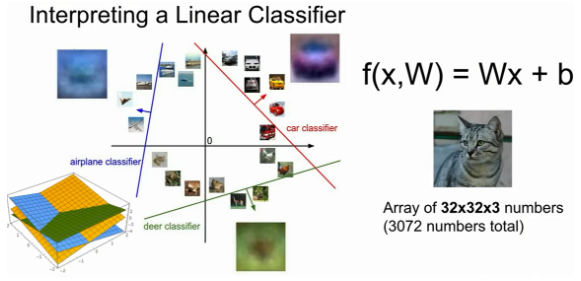
Linear Classifier의 단점
이미지 변동이 있어도 그것의 평균을 결과로서 보여준다.
그래서 말 카테고리의 이미지를 보면 말의 머리가 두개가 나타난다.
Multimodal problem: 선형으로 분류할 수 없는 데이터에 사용하기 어렵다.
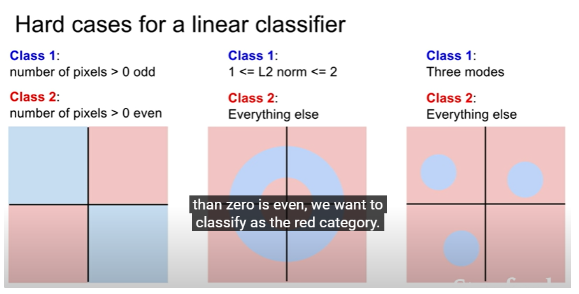
KNN과 Linear Classifier의 차이점
KNN
시작할 때 파라미터가 없다.
테스트 할 때 전체 train set을 가지고 테스트를 한다.
Linear Classifier
테스트 할 때 train set의 전체 데이터는 필요없고 train의 결과인 w을 가지고 테스트를 한다.
KNN보다 효율적
'Group Study (2022-2023) > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 3주차 스터디 - Softmax Regression (0) | 2022.10.31 |
|---|---|
| [Machine Learning] 4주차 스터디 - Application & Tips (0) | 2022.10.31 |
| [Machine Learning] 2주차 스터디 - Multi variable linear regression & Logistic Regression (0) | 2022.10.10 |
| [Machine Learning] 2주차 스터디 - CNN의 이해(2) (0) | 2022.10.10 |
| [Machine Learning] 1주차 스터디 - 머신러닝의 용어와 개념 & 선형 회귀(Linear Regression) (0) | 2022.10.04 |